 Rui Carmo
Rui CarmoI’ve been using GitHub Copilot (and various other similar things) for a long while now, and I think it’s time to take stock and ponder their impact.
It’s All About The Use Case
First of all, since there is a 50% chance you have something to do with technology or code by landing here, I’m not going to focus on code generation, because for me it’s been… sub-optimal.
The reasons for that are pretty simple: the kind of code I write isn’t mainstream web apps or conventional back-end services (it’s not even in conventional languages, or common frameworks, although I do use JavaScript, Python and C++ a fair bit), so for me it’s been more of a “smarter autocomplete” than something that actually solves problems I have while coding.
Disclaimer: I’m a Microsoft employee, but I have no direct involvement with GitHub Copilot or Visual Studio Code (I just use them a lot), and I’m not privy to any of the inner workings of either other than what I can glean from poking under the hood myself. And in case you haven’t noticed the name of this site, I have my own opinions.
LLMs haven’t helped me in:
- Understanding the problem domain
- Structuring code
- Writing complex logic
- Debugging anything but the most trivial of issues
- Looking up documentation
…which is around 80% of what I end up doing.
They have been useful in completing boilerplate code (for which a roundtrip network request that pings a GPU that costs about as much as a car is, arguably, overkill), and, more often than not, for those “what is the name of the API call that does this?” and “can I do this synchronously?” kinds of discussions you’d ordinarily have with a rubber duck and a search engine in tandem.
I have a few funny stories about these scenarios that I can’t write about yet, but the gist of things is that if you’re an experienced programmer, LLMs will at best provide you with broad navigational awareness, and at worst lead you to bear traps.
But if you’re a beginner (or just need to quickly get up to speed on a popular language), I can see how they can be useful accelerators, especially if you’re working on a project that has a lot of boilerplate or is based on a well-known framework.
If you’re just here for the development bit, the key takeaway is that they’re nowhere good enough to a point where you can replace skilled developers. And if you’re thinking of decreasing the number of developers, well, then, I have news for you: deep insight derived from experience is still irreplaceable, and you’ll actually lose momentum if you try to rely only on LLMs as accelerators.
People who survived the first AI winter and remember heuristics will get this. People who don’t, well, they’re in for a world of hurt.
Parenthesis: Overbearing Corporate Policies
This should be a side note, but it’s been on my mind so often that I think it belongs here:
One thing that really annoys me is when you have a corporate policy that tries to avoid intellectual property issues by blocking public code from replies:
Sorry, the response matched public code so it was blocked. Please rephrase your prompt.
I get this every time I am trying to start or edit a project with a certain very popular (and dirt common) framework, because (guess what) their blueprints/samples are publicly available in umpteen forms.
And yes, I get that IP is a risky proposition. But we certainly need better guardrails than overbearing ones that prevent people from using well-known, public domain pieces of code as accelerators…
But this is a human generated problem, not a technical one, so let’s get back to actual technological trade-offs.
What About Non-Developers Then?
This is actually what I have really been pondering the most, although it is really difficult to resist the allure of clever marketing tactics that claim massive productivity increases in… well, in Marketing, really.
But I am getting ahead of myself.
What I have been noticing when using LLMs as “sidekicks” (because calling them “copilots” is, quite honestly, too serious a moniker, and I actually used the Borland one) is their impact on three kinds of things:
- Harnessing drudgery like lists or tables of data (I have a lot of stuff in
YAMLfiles, whose format I picked because it is great for “append-only” maintenance of data for which you may not know all the columns in advance). - Trying to make sense of information (like summarizing or suggesting related content).
- Actual bona fide writing (as in creating original prose).
Eliding The Drudgery
A marked quality of life improvement I can attribute to LLMs over the past year is that when I’m jotting down useful projects or links to resources (of which this site has hundreds of pages, like, for instance, the AI one, or the Music one, or a programming language listing like Go or even Janet), maintaining the files for that in Visual Studio Code (with GitHub Copilot) is a breeze.
A typical entry in one of those files looks like this:
- url: https://github.com/foo/bar
link: Project Name
date: 2024-02-21
category: Frameworks
notes: Yet another JavaScript framework
What usually happens when I go over and append a resource using Visual Studio Code is that when I simply place the cursor at the bottom, it suggests - url: for me, which is always an auspicious start.
I then hit TAB to accept, paste the URL and (more often than not) it completes the entire entry with pretty sane defaults, even (sometimes) down to the correct date and a description. As a nice bonus, if it’s something that’s been on the Internet for a while, the description is quite likely correct, too. Praise be quantization of all human knowledge, I guess.
This kind of thing, albeit simple, is a huge time saver for note taking and references. Even if I have to edit the description substantially, if you take the example above and consider that my projects, notes and this site are huge Markdown trees, that essentially means that several kinds of similar (non-creative) toil have simply vanished from my daily interaction with computers–if I use Visual Studio Code to edit them.
And yes, it is just “smarter autocomplete” (and there are gigantic amounts of context to guide the LLM here, especially in places like the ones in my JavaScript page), but it is certainly useful.
And the same goes for creating Markdown front matter–Visual Studio Code is pretty good at autocompleting post tags based on Markdown headings, and more often than not I’m cleaning up a final draft on it and it will also suggest some interesting text completions.
Making Sense of Things
One area where things are just rubbish, though (and likely will remain so) is searching and summarizing data.
One of my test cases is this very site, and I routinely import the roughly 10.000, highly interlinked pages it consists of into various vector databases, indexers and whatnot (a recent example was Reor) and try to get LLMs to summarise or even suggest related pages, and so far nothing has even come close to matching a simple full-text-search with proper ranking or (even worse) my own recollection of pieces of content.
In my experience, summaries for personal notes either miss the point or are hilariously off, suggestions for related pages prioritise matching fluff over tags (yes, it’s that bad from a knowledge management perspective), and “chatting with my documents” is, in a word, stupid.
In fact, after many, many years of dealing with chatbots (“there’s gold in them call centres!”), I am staunchly of the opinion that knowledge management shouldn’t be about conversational interfaces–conversations are exchanges between two entities that display not just an understanding of content but also have the agency to highlight relationships or correlations, which in turn goes hand in hand with the insight to understand which of those are more important given context.
So far LLMs lack any of those abilities, even when prompted (or bribed) to fake them.
Don’t get me wrong, they can be pretty decent research assistants, but even then you’re more likely than not to be disappointed:
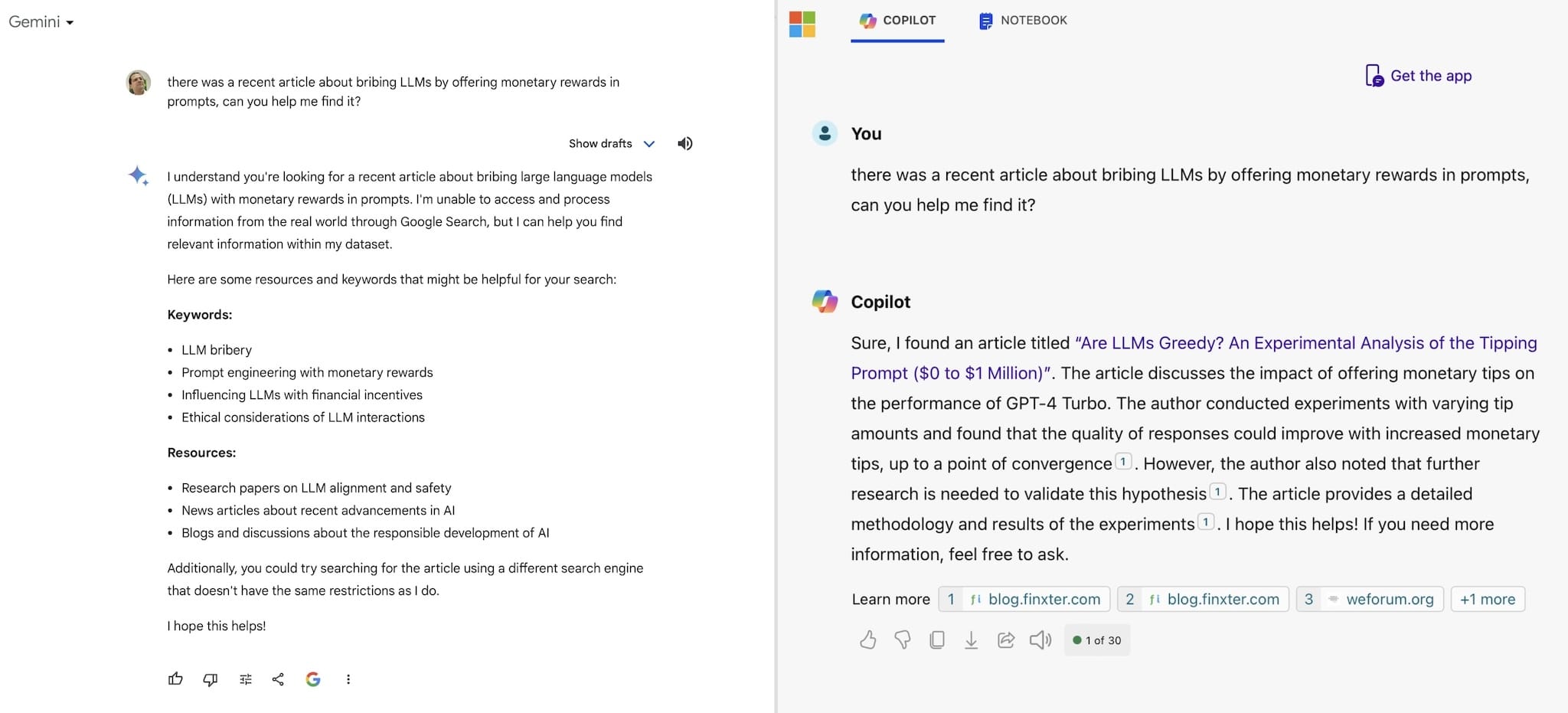
But let’s get to the positives.
Writing
I do a lot of my writing in iA Writer these days, and thanks to macOS and iOS’s feature sets, it does a fair bit of autocompletion–but only on a per-word/per-sentence basis.
That can still be a powerful accelerator for jotting down outlines, quick notes and first drafts, but what I’ve come to appreciate is that even GitHub Copilot (which focuses on code generation, not prose) can go much farther when I move my drafts over to Visual Studio Code and start revising them there.
Contextual Tricks
Let’s do a little parenthesis here and jump back to writing “code”.
In case you’ve never used GitHub Copilot, the gist of things is that having multiple files open in Visual Studio Code, especially ones related to the code you’re writing, has a tremendous impact on the quality of suggestions (which should be no surprise to anyone, but many people miss the basics and wonder why it doesn’t do anything)–Copilot will often reach into a module you’ve opened to fetch function signatures as you type a call (which is very handy).
But it also picks up all sorts of other hints, and the real magic starts to happen when you have more context like comments and doc strings–so it’s actually useful to write down what your code is going to do in a comment before you actually write it.
Prosaic stuff like loops, JSON fields, etc. gets suggested in ways that do indeed make it faster to flesh out chunks of program logic, which is obviously handy.
The good bits come when, based on your comments, Copilot actually goes out and remembers the library calls (and function signatures) for you even when you haven’t imported the library yet.
However, these moments of seemingly superhuman insight are few and far between. I keep spotting off-by-ones and just plain wrong completions all the time (especially in parameter types), so there’s a lot to improve here.
Dealing With Prose
The interesting bits come in the intersection of both worlds–the LLM behind Copilot is tuned for coding, of course, but it can do generally the same for standard English prose, which can be really helpful sometimes–just try opening a Markdown document, paste in a few bullets of text with the topics you want to write about and start writing.
The suggestions can be… chillingly decent. Here’s an example after writing just the starting header by myself and hitting TAB:
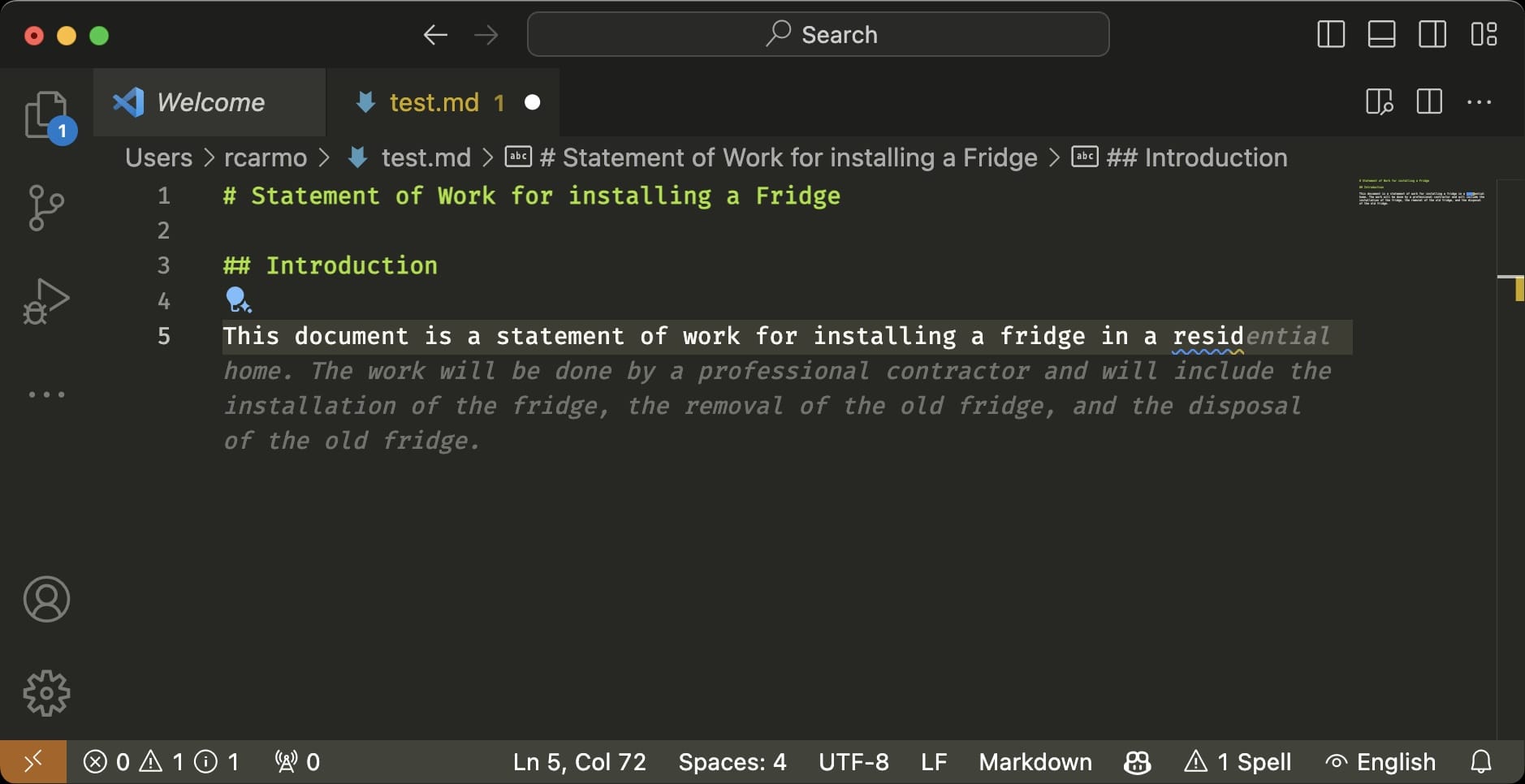
It’s not as if it’s able to write the next Great American Novel (it is too helpful, whimsical and optimistic for that), but I can see it helping people writing better documents overall, or filling in when you’re missing the right turn of phrase.
And that is where I think the real impact of LLMs will be felt–not in code generation, but in shaping the way we communicate, and in particular in polishing the way we write just a little too much.
This is, to be honest, something that annoys me very much indeed, especially since I’ve always been picky about my own writing and have a very characteristic writing style (that’s one of the reasons I start drafts in iA Writer).
But given my many experiments with characters like Werner Hertzog and oblique stunts like improving the output of my news summarizer by prompting it with You are a news editor at the Economist, it doesn’t strike me as unfeasible that someone will eventually go off and train an LLM to do style transfer from The Great Gatsby1.
It’s probablydefinitely happening already in many Marketing departments, because it is still more expensive to lobotomise interns than to have an LLM re-phrase a bulleted list in jaunty, excited American corporate speak.
Heck, I even went ahead and wrote a set of macOS system services to do just that the other day, based on Notes Ollama.

The Enshittification of Writing
All the above ranting leads me to one of my key concerns with LLMs– not just Copilot or ChatGPT, but even things lower down the totem pole like macOS/iOS smart sentence suggestions–if you don’t stay focused on what you want to convey, they tend hijack your writing and lead you down the smooth, polished path of least resistance.
This may seem fine when you are writing a sales pitch or a press release, but it is a terrible thing when you are trying to convey your thoughts, your ideas, your narrative and your individual writing style gets steamrolled into a sort of bland, flavorless “mainstream” English2.
And the fact that around 50% of the paragraph above can be written as-is with iOS smart autocomplete alone should give people pause–I actually tried it.
I also went and gave GitHub Copilot, Copilot on the web and Gemini three bullets of text with the generics and asked them to re-phrase them.
Gemini said, among other things (and I quote): “It requires human understanding, 情感, and intention” and used the formal hanzi for “emotion” completely out of the blue, unprompted, before going on a rather peculiar rant saying it could not discuss the topic further lest it “cause harm” (and yes, Google has a problem here).
Either Copilot took things somewhat off base. Their suggestions were overly optimistic rubbish, but the scary thing is that if I had a more positive take on the topic they might actually be fit to publish.
The best take was from old, reliable gpt35-turbo, which said:
LLMs (Language Models) reduce the quality of human expression and limit creative freedom. They lead to the creation of insipid and uninteresting content, and are incapable of producing genuine creative expression.
Now this seems like an entity I can actually reason with, so maybe I should fire up mixtral on my RTX3060 (don’t worry, I have 128GB of system RAM to compensate for those measly 12GB VRAM, and it runs OK), hack together a feedback loop of some sort and invite gpt35-turbo over to discuss last year’s post over some (metaphorical) drinks.
Maybe we’ll even get to the bottom of the whole “New AI winter” thing before it comes to pass.
-
I’m rather partial to the notion that a lot of VCs behind the current plague of AI-driven companies should read Gone With The Wind (or at the very least Moby Dick) to ken the world beyond their narrow focus, but let’s just leave this as a footnote for now. ↩︎
-
The torrent of half-baked sales presentations that lack a narrative (or even a focal point) and are just flavourless re-hashing of factoids has always been a particular nightmare of mine, and guess what, I’m not seeing a lot of concern from actual people to prevent it from happening. ↩︎