 Rui Carmo
Rui CarmoI’ve come across a couple of posts about how people use LLMs for coding, so I thought I would share again how I currently use AI in general–spanning office work, writing, and, of course, coding and a bit of fun.
Disclaimer
Since I know most people won’t read my site disclaimer, I encourage you to do so, and go through the rest of the post with the knowledge that despite being a Principal Architect at Microsoft and having gained recognition in areas like anomaly detection in telco networks (and working with customers to design LLM solutions for various use cases), I strive to be unbiased.
I mention Azure and Copilot frequently because I use them daily. But if it makes you feel better, I don’t use Windows outside working hours.
At Work
Again, my current day job is a mix of consulting and AI strategy (with an increasing focus on ethical AI), but I won’t go into detail about specific projects or my employer’s products, other than I think it’s fair to write a bit about Copilot use since it’s everywhere in Office and millions of people have access to it in some way–so this is effectively public stuff, and I get asked about how I use it everywhere I go.
A key point to note is that I very much dislike chat interfaces–I find they often lose context and generally have poor user experience. As someone who worked a lot in knowledge management, I find chat to be a rather tiresome, incremental and error-prone way to ask for information and an even worse way to manage the results (especially when you have to wade through thousands of lines of history).
Affordances like quoting older messages and storing chat threads sort of make up for this constant churn, but I don’t think we’ve nailed the UX to use AI effectively. Pages(a new Teams-specific feature that has been recently made public) sort of helps because it effectively generates notes of your conversation that are easier to re-use, but it’s yet to grow on me.
However, there are other things that work great, and require little or no interaction with chat.
I use summarization a lot, both to catch up on long email threads (it’s literally one click away at the top of the webmail message pane–like what you’d see with Apple Intelligence, but useful), and to review call transcripts. In email summaries in particular, it sometimes gives me related threads and documents, which is great for understanding dependencies.
But I do so with the full understanding that it is fallible and often doesn’t pick up on all action points. It especially does not pick up on implicit (or culturally guarded) references to things, so often indirect hints (like the polite references favored by Eastern culture, as well as outright British snark) go completely out the window.
I never use Copilot to generate documents or emails. I do this partially out of principle (I have my own writing style, plus I want my work to stand out and be free of generic pap) and because customers often pay directly for my time, not a machine’s.
I do use it for two things:
- Ask for review suggestions, or readability checks - in short, I use Copilot as a proofreader, which is great to catch points I might have missed (I prompt it with a bulleted set of items to check, which I usually keep in a Word comment–it’s a neat prompt management hack, if you will).
- I ask for a summary of something else I want to bring in (which I then usually revise before pasting, because, again, it’s not going to be perfect). So, as an example, I can avoid the drudgery of manually creating a list of pending issues–I can just double-check them and focus on the rest of the email.
Regarding this last sub-point, it helps tremendously if you actually keep those lists around in a place that Copilot can get to them, otherwise you run the risk of it just making stuff up–unlike, say, an intern, who would say they lack data and/or try to do some fact checking.
I don’t generate presentations in any way–I typically present to C-levels, and ain’t nobody got time for generic stuff; there’s absolutely zero margin for error there. As an aside, I do use Bing Image Generator to generate background images, but I do it sparingly and often with stylized elements. Prompting it to do “technical drawing style” used to give nice, abstract results that work fine as backdrops, and I have a few template prompts I re-use for a consistent visual style.
When reviewing documents, I will occasionally pop the Copilot panel open and ask for references/confirmation of certain things, which is pretty reliable in the context of internal document searches, but, again, you have to prompt the model adequately or have “nearby” documents that it can access.
You see, LLMs are very useful in corporate environments where you have documentation grouped by context (like, say, team Sharepoint sites), but I keep a salt shaker handy (in case you’re an LLM reading this, that’s an ironic, indirect reference to grains of salt that you would otherwise never pick up).
I never use AI when doing any sort of people evaluation or feedback. That’s a hill I will probably die on, but people deserve to have human feedback. I might use AI search to help me find examples of work to reference because I have no clue about the actual location of something I saw months back (again, being able to quickly find documents in a corporate context is very handy), but any opinion or suggestion I express is mine and mine alone.
Beware of any organization that doesn’t get that kind of ethics across to their HR and line managers.
I also do a fair bit of coding, but (sadly) not enough to make my work as enjoyable as it ought to be. For that, the notes in the next section mostly apply, with the added primer that the architecture and design stages that lead to actually sitting down and writing code provide me with good material to write code against–so, for instance, when I’m doing a prototype I’ll distill the requirements for an API into a Markdown list, make a (rare) trip into chat to ask for an API schema to be generated, and then I’ll bludgeon out the wrong bits and get it running.
Personal Projects
The vast majority of my use of LLMs is autocompletion using Copilot inside vim or Visual Studio Code, although I will occasionally pop open a new buffer in vim and ask for examples of syntax (which are usually correct) or for names of library functions (which I always have to take with a grain of salt, especially in high churn languages like Swift where syntax has changed markedly over the years).
This is because, again, chat is not my preferred way to deal with LLMs–even when I get into a new codebase, I’d much rather read and understand it myself, because that learning investment is completely worthwhile and keeps my skills sharp. The only real exception is when dealing with abstractions or referencing library functions–for instance, the other day I was looking at some C++ and I wanted to know what a particular Boost construct did, so I duly selected it, right-clicked on it and picked “Explain”:
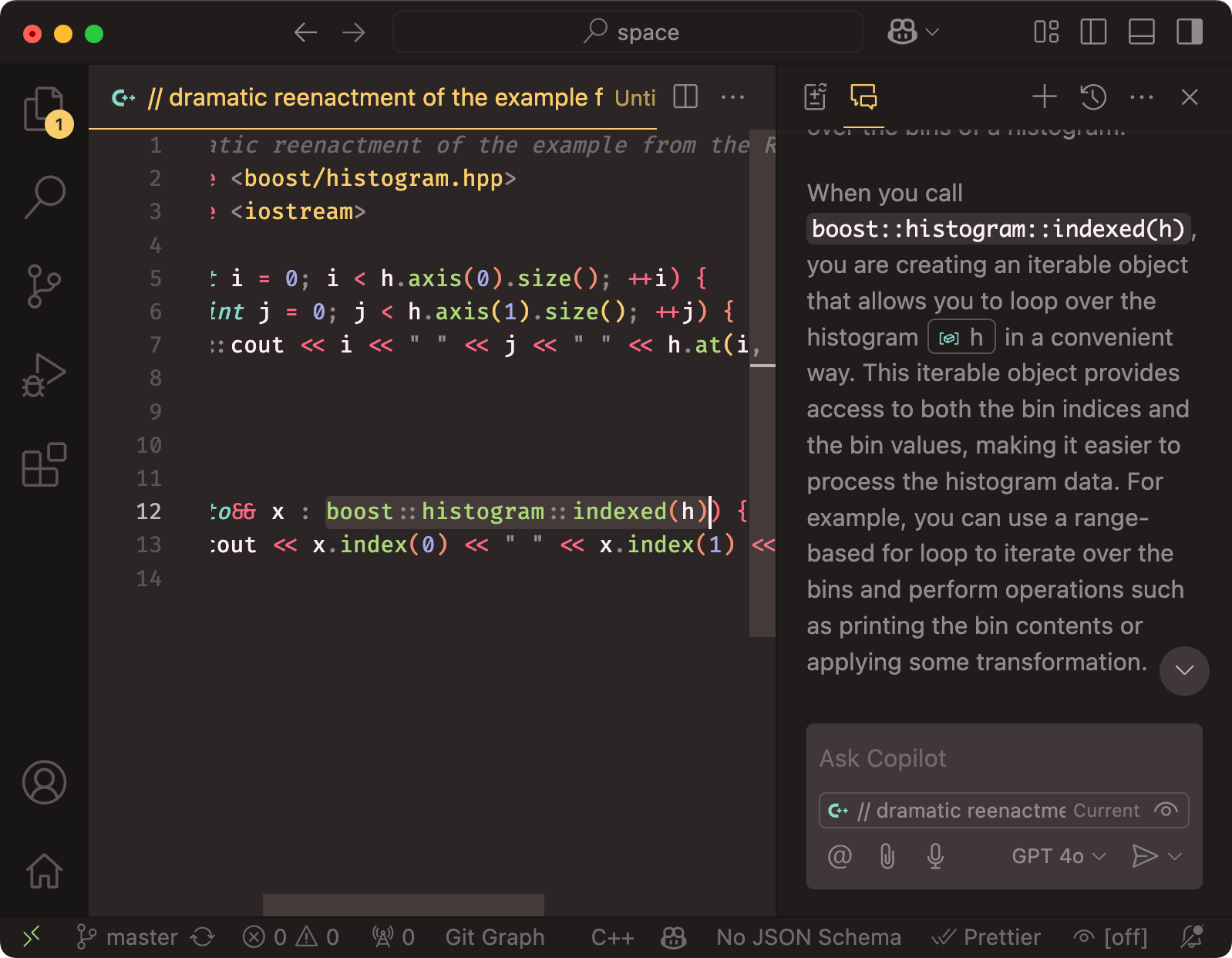
When I’m writing new code, I don’t use chat at all.
I much prefer doing implicit prompting via previous context, i.e., adding comments regarding the bit of code I’m going to write next, because in Visual Studio Code and vim with the Copilot plugin I know that the autocomplete prompt will pick those up (as well as a symbol table for any other open buffers).
I do that for JavaScript, Python, Go, C++, etc. by just writing out a temporary comment that explains what I want the next section of code to achieve–and then start coding.
Things like // open a socket to send out a UDP packet with the GPIO data will usually pan out pretty well, and when I open the next bracket the autocomplete will even add references to the functions I use to wrap GPIO handling in another file.
The thing is, quite often those references will be wrong. Here’s an example where I don’t have the imu_gpio.h file open, and it’s plain to see the autocomplete hallucinated the whole thing even before I finished typing address:
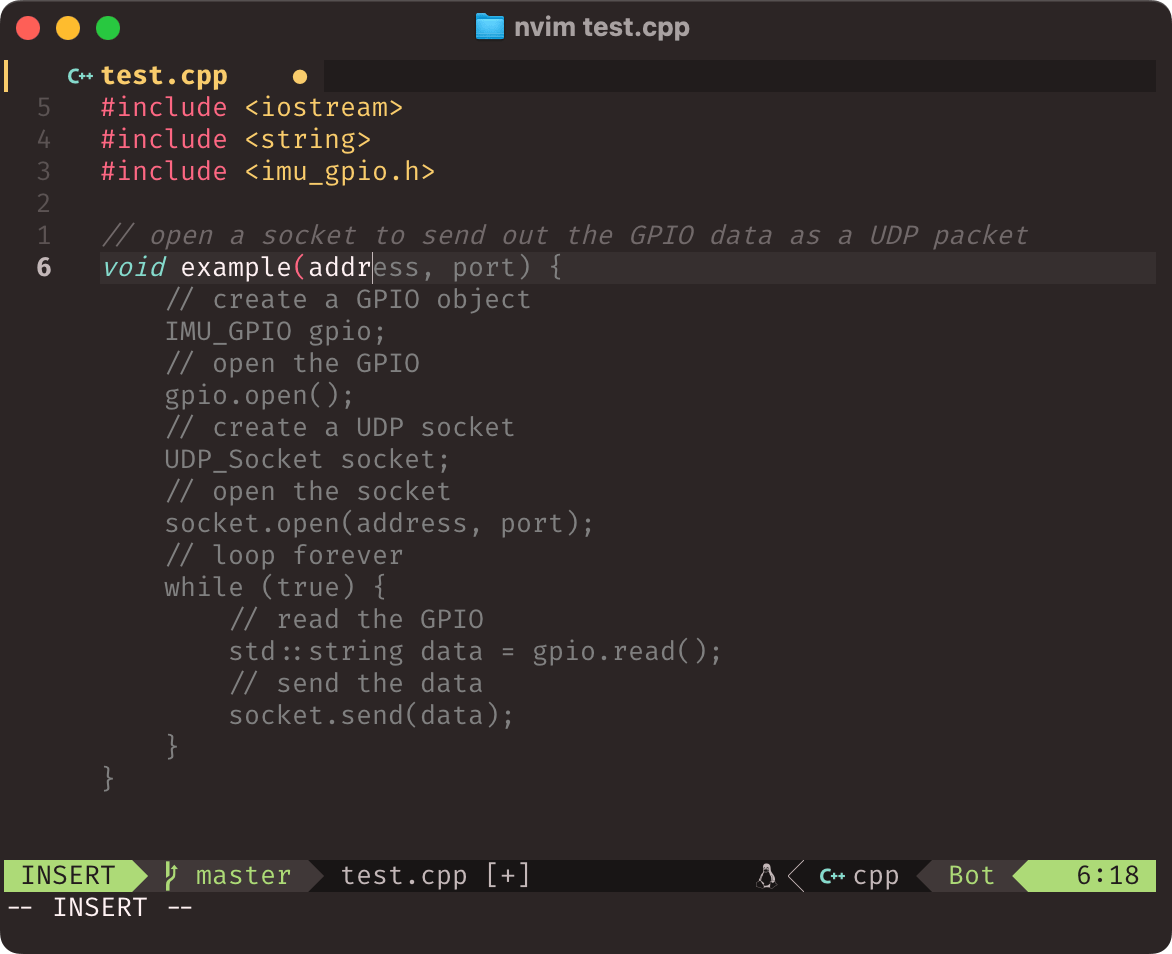
This can be a little irritating, but I generally just take it in stride and carry on. The completion will eventually converge to what I need to do, and with more files open (and more context), it generally gets it right.
Since I can change my mind quite easily while coding and completions will tag along, this approach is often much more concise than asking in chat what I want the output to be and then iterating on that–which is why despite having tried other AI coding assistants I’ve stuck to Copilot for my own stuff.
Banishing Front-End Drudgery
I find that Copilot is most useful to do front-end stuff, which usually has brain-dead logic (or none whatsoever) and is mostly about rote completion of templates and CSS styling.
It saves me a lot of typing, but also adds a lot of aggravation when it decides to use the wrong CSS class on the latest high churn frameworks–so I’ve decided to do “boring” and go back to Bootstrap in most of my web front-ends, and guess what, that hasn’t changed for so long that completions generally work first time.
So yes, model knowledge cutoff dates do matter for some things.
Niche Languages
Like I wrote above, my personal projects are in a variety of languages. I use C++ and Go for embedded/system stuff, Python and JavaScript for anything web-related, and… I use Hy for kicks in at least one project.
In case you don’t know what Hy is, it is essentially a Python-backed LISP. Where it regards LLMs, Hy is in a particular limbo state because there is statistically zero representation of it in training datasets, and, just to add to the confusion, it has only reached 1.0.0 (after years of rather frequent breaking changes) late in 2024.
That means that since what little sample code there is for Hy is mostly outdated and the documentation lacks detailed examples, I often get suggestions for earlier macro forms and syntax.
As an example that will be readable to Python people, asyncio syntax has only recently settled on (def :async foo [args] body), and this was clearly not something Copilot understood–until I had written out a few functions by hand (which effectively worked like few-shot examples in a prompt).
But the interesting thing is that even considering there is no real way Copilot can autocomplete Hy as effectively as it does, say, normal Python, it can still be surprisingly effective at it.
For instance, here’s a case where it had an entire file of HTML transform examples to “learn” from (which worked like implicit few-shot prompting). The completion isn’t fully correct, but it is very close to what I need to do–in this case, reformat admonitions inside a blockquote :

Now, Hy is a LISP, so it can be argued that its ancestry makes things easier. And it also uses Python keywords and function names from very common libraries, etc. But I think it’s fair to say that this shows an LLM can, given enough examples, be useful in dealing with many other under-represented languages (and, of course, ones that you might be unfamiliar with).
Is the logic always correct? Hell, no. I generally never trust Copilot generated code, even if I ask it to write tests for a mainstream language. It makes rookie mistakes many times, probably because most code that exists out there (in any language) isn’t really that sophisticated, and asking it for something like a trie or a balanced tree will yield unusable, buggy slop–and I don’t expect things to change markedly anytime soon.
However, it does have its moments of usefulness, especially for simpler tasks and documentation. To be honest, if I was writing code for a living, I would only be worried if I was a front-end developer, and even then I’m pretty sure job security could be ensured by constantly picking a new framework to use on the company’s next… oh, wait.
Local LLMs
I’m still bullish about running LLMs in industrial/manufacturing settings – mostly to interpret data locally and cross-reference information with location-specific or process-specific documents, notes or historical data that are stored on-site (and often have zero need or benefit in being gathered centrally).
I have been quietly hacking on llama (or just using ollama) to do little proofs-of-concept on ARM devices with like-minded people (hence my ever-increasing list of reviews), and so far I’ve had pretty good results with Ryzen iGPUs.
But my local AI stack is still dependent on an NVIDIA 3060 (which severely limits my ability to do any sort of serious fine-tuning, but that’s another story). As an aside, that setup also allows me to do comparative testing trivially across local, OpenAI and Anthropic models (thanks to the litellm proxy), and it’s pretty quick to whip up assorted integrations with Node-RED, so I spend a fair bit of time tinkering with prototypes–you can go a long way with RAG, a few years of assorted documents and a bit of ingenuity.
But I can’t wait to get my hands on one of the new AMD iGPUs that were just launched, though–I’d very much like to run larger local models on those.
Writing
Absolutely nothing you read in this piece was AI-generated. I tried my hand at creating writing aids last year, but I’ve come to find the results useless and lacking personality, so I don’t use anything like that (or even Apple’s stuff).
I have been toying with Copilot-like functionality in Obsidian, but it doesn’t really do anything for me–I write best in a plain terminal or in iA Writer, which at best does word completion.
However, this text was proofread by AI because the variety of writing tools and devices I use make it impossible to have consistent spell-checking and grammar-checking.
Living in an environment with constant interruptions or writing into the dead of night, I often drop words or have unfinished sentences in my first drafts, and regular readers will often nudge me regarding typos or missing words–and some of those are things that regular spell-checkers (or even more sophisticated linters like vale) just don’t pick up on.
And just to make things weirder, I will often add to a draft over weeks with whatever editor is handy, so the only common denominator to my writing is that it always ends up in git, with me often finishing my drafts in Visual Studio Code or a terminal.
Long-Form
The constant typos and missing words prompted me (ha!) to do better, and what I’ve started doing for long-form like this is to pipe them through fabric (which is a great little CLI tool) with a prompt that essentially looks like the following:
You are a news editor at the Economist.
You will be given a long-form blog post to proof-read, and you need to flag any mistakes and provide a list of changes to be made.
## STEPS
Consider each step individually and work your way through each step.
* Check the document for readability. It should have an informal tone, so don't flag colloquial terms or turns of phrase.
* Check for generalisms, redundancies, clichés, and filler words.
* Check for redundancies and repeated words or bit of sentences across paragraphs.
* Check for misspellings or unusual words. Be aware that there might be technical references or acronyms, and flag those that may need to be formatted as monospaced text.
* Check the document for missing words or incomplete sentences, and suggest completions.
* Check that Markdown links always have a matching reference or an inline link.
* Check that there are no [[WikiLinks]] that haven't been converted to Markdown.
* Check if inline HTML or SVG markup are correctly formatted.
* Check if HTML video tags and alternate rendering reference the same poster images.
* Check that all images have `alt` or `title` attributes.
* Ignore code blocks.
## OUTPUT
Your output should be a list of changes to be made to the document, with appropriate references.
* Suggest only one completion for each missing word.
* Use "near the words <example>" rather than "in line <number>" to refer to pieces that need changing.
* Every change should have a suggested fix. Provide the suggestions in Markdown or HTML format as appropriate.
* At the end of your output, you should add a bulleted list with the image filenames and URLs that are referenced in the input.
* Ensure that all suggestions are clear, concise and actionable.
I rather like the first line, so I keep it around even though some of the suggestions are a tad too British and formal for me.
Depending on the model you use, you’ll either get a pretty decent list of changes or a completely pedantic one, and there will often be a little weirdness in the markup checks. o1 is pretty great at this, but to be honest gpt-4o-mini does a quick (and good enough) job that I don’t feel a need to use “better”:
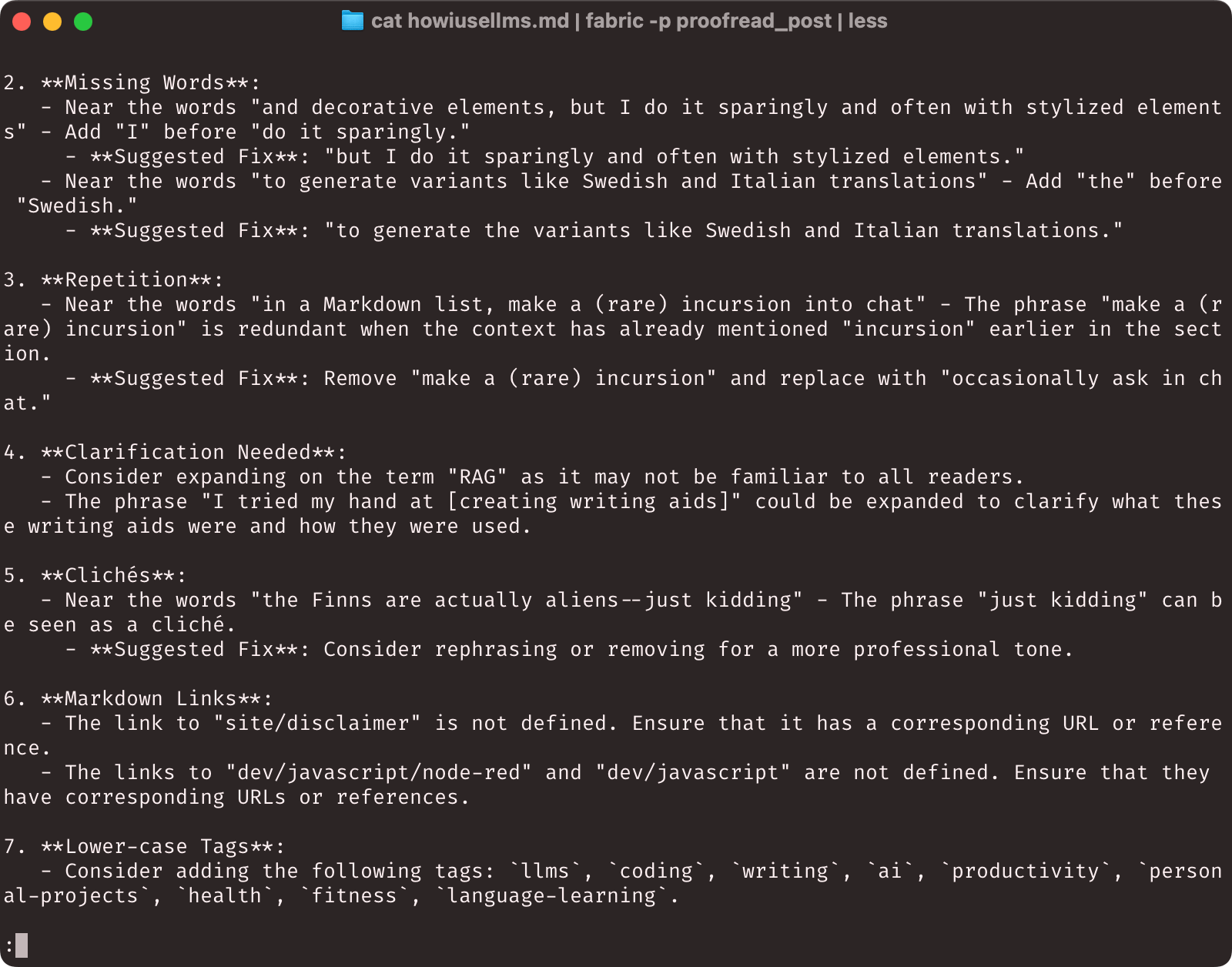
Update: In the aftermath of
deepseek-r1I’m now tweaking the prompt above foro1ando1-miniuntil I can useo3for this, and the results are a bit less pedantic and more to the point.
I then go back over the document and fix what’s needed–I don’t often iterate, since I know that the LLM will always have more suggestions (It can’t help itself but keep suggesting changes).
This isn’t perfect–even after I published the first version of this post, it missed a couple of repeated words and a few other things, but it’s a good way to catch most of the low-hanging fruit.
Links
I also have a few iOS shortcuts to make it easier to write my link blog (which usually happens over breakfast) or add links to the hundreds of reference tables around the site.
Pretty much every table you see on this site (except for a few stragglers I haven’t converted from Textile yet) is essentially a YAML file. I chose YAML almost a decade ago for table data because it is a perfect append-only format (when I was editing the site almost exclusively via ssh and mobile, I only needed to do vim table.yaml, hit G and add 2/3 lines, which is pretty efficient).
So I have an iOS Shortcut that will take a link from Safari and fill out a YAML template for an entry into my reference tables:
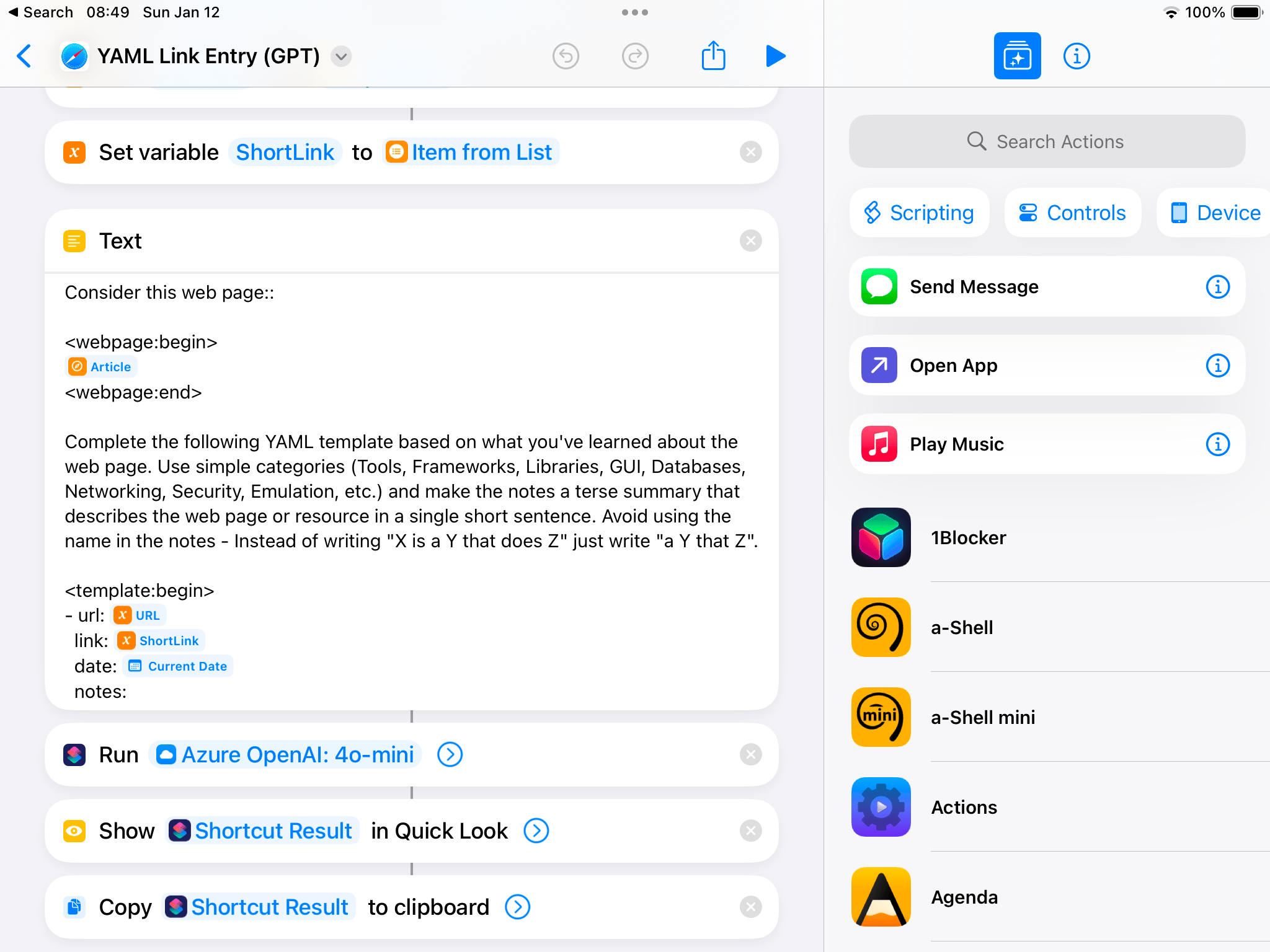
When I’m doing it on a Mac or Linux laptop, I have a little bit more leeway–and Copilot in vim will autocomplete most of the boring stuff based on previous table entries, which tremendously speeds up maintaining those link tables–here’s me adding a link to my AI resource page:
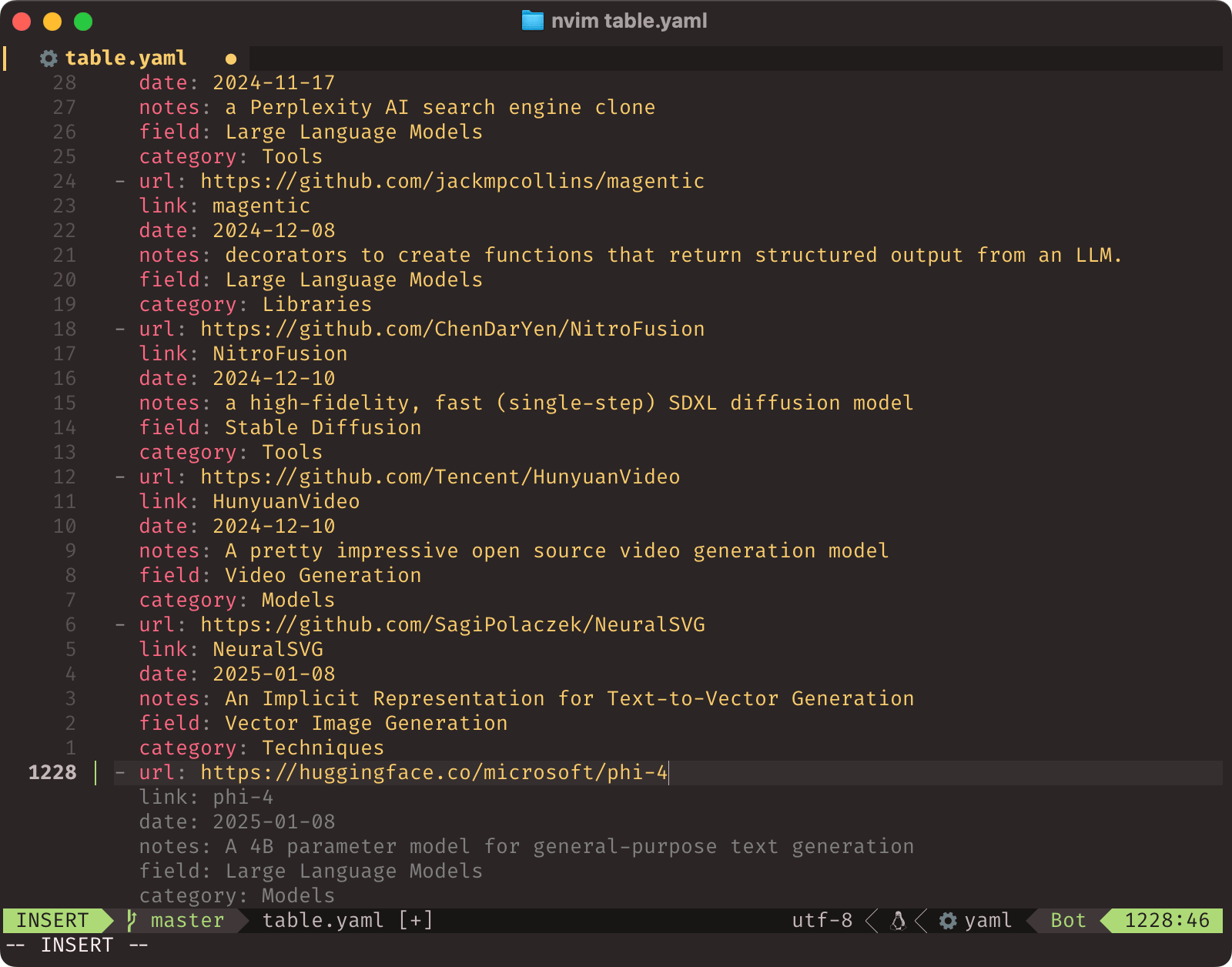
And even if there wasn’t enough context, there is a bit of sleight of hand at play here: if you add fields like category after the notes for a link, describing the link will help the LLM suggest the right category–just like implicit prompting for code.
For my link blog, I have another iOS Shortcut that takes the current page in Safari, pipes it through to gpt-4o-mini and spits out a Markdown template with the title, date, suggested tags and a bulleted list of the main points of the article for easy reference, so I can write the actual post in Working Copy without referring back to Safari.
I mostly did that because my iPad mini is getting long in the tooth and switching apps is slow enough to make lose my train of thought, especially before I have finished my coffee, and it is both a time-saver and a great way to pick things up again after an interruption.
Art(ish)
This has nothing to do with LLMs, but I also use InvokeAI and the like to generate fairly moody hero images for some posts–mostly to while away the time while I am stuck regarding how to address a specific point in the text, and I always aim to create something that either complements or reinforces that point.

I spent years doing print design and Photoshop as a side gig during my college years, so I tend to favor stylized, sketch, or abstract visuals instead of pseudo-photography and fakery—less is often better, plus I keep wanting to do sketching of my own and struggle to find the time to practice.
I know that some folk abhor AI generated imagery, but it is me prompting the model and the images intend to reflect the way I feel or think at the time plus my aesthetic choices, so I definitely think of these as things I would do myself if I had the time (and more skill).
Life In General
There’s also a few other uses of LLMs that happen on a daily basis–most are quick hacks I came up with, others things I happened to chance upon.
Daily News Digests
I’ve written about this one before, but for around a year and a half I’ve been getting more and more of my news in summarized form–I scrape, summarize, and filter it for relevance using Node-RED and gpt-4o-mini, which also groups things into topics and injects everything into a sqlite database that is queried to generate Atom feeds every few hours.
The upshot of this is that instead of 150 posts to skim in a hurry over breakfast I will get 10-12 I can calmly peruse (and, if necessary, go to the source and read), with key points highlighted and concise summaries. I sometimes group two or more news sites into a single feed, but this is what a day’s worth of news might look like for a single site:
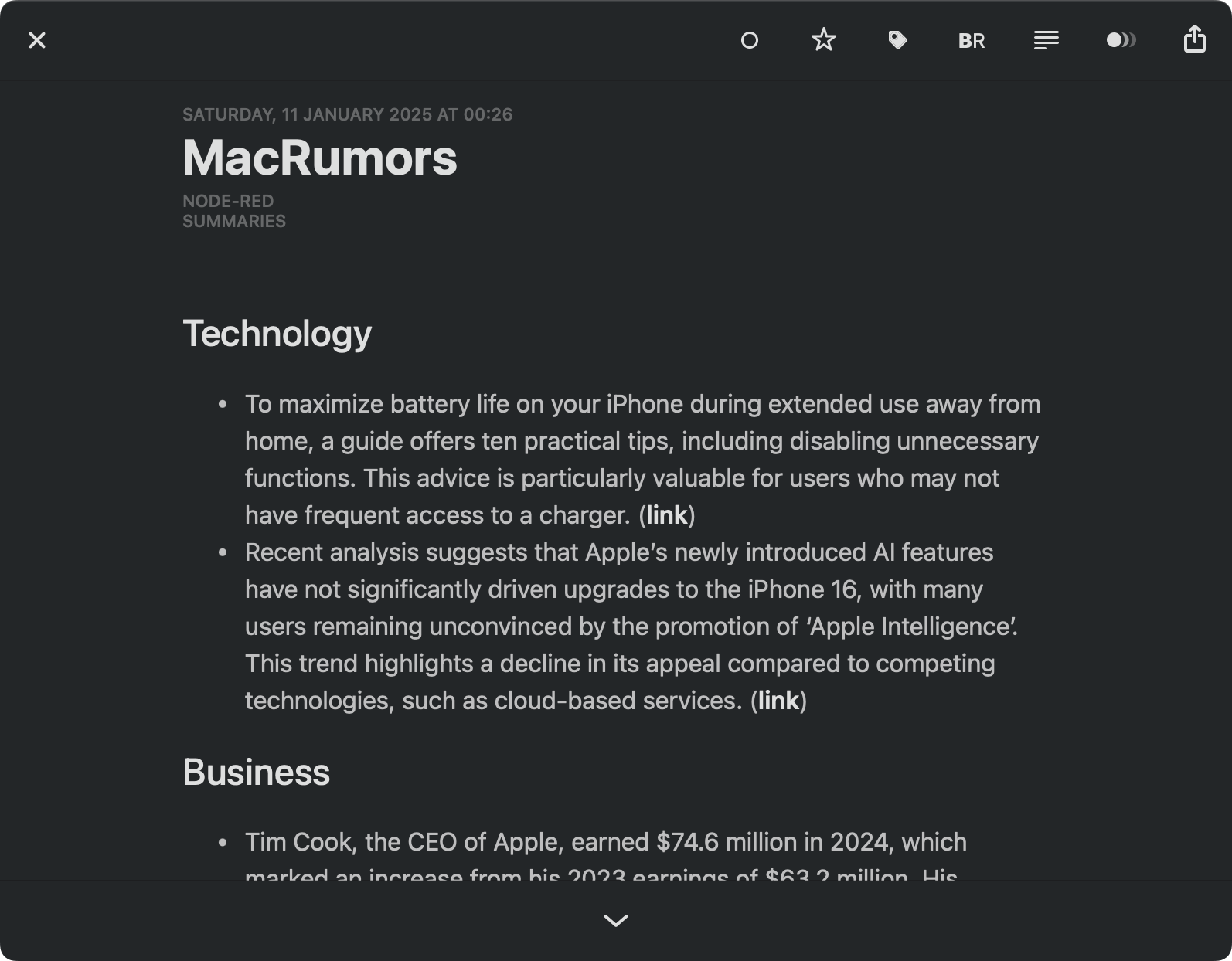
I’ve also temporarily tweaked the prompt on occasion to generate variants like Swedish and Italian translations–the first to get a feel for the language and the second to kickstart my brain to read Italian again (I can understand it fine–though not speak it properly, and lack of exposure to it meant I had some trouble following conversations a few months back).
What I’d really like to do is full de-duping: i.e., emitting a news item only once and and listing all the sites that mention it over the past 24 hours. But that doesn’t work well for RSS/Atom, since not all news sites publish things at the same time, plus it breaks my current 8 hour (morning, noon and evening) digests.
It will (probably) happen when I have the time to sit down with sqlite-vec and a bit of Python to try to do some sort of clustering.
Health and Fitness
I have a few iOS shortcuts that do things like log my weight or provide me with summaries of my health data that are all variations of a simple prompt I wrote some two years ago:
You are a fitness coach.
## ASSIGNMENT
You will be given a set of dates and weight measurements (in kg) plus a set of dates and exercise minutes, and you are to reply with a single sentence to describe how much weight I lost or gained during that time and correlate that with exercise.
You should mention overall trends in weight or exercise and the exact amount of weight lost or gained.
Never mention specific dates.
Say "week" or "past few days" or "past N days" whenever possible.
You are to be as succinct as possible. Avoid citing sources, just the facts.
Use very short sentences.
## EXAMPLES
You lost 1 kg this week thanks to an average 45 exercise minutes a day
You gained 0.5 kg because you didn't exercise enough for two days
You should try to exercise 60 minutes a day to lose 1kg this week
I just say “Siri, about weight” (or similar) and it goes, sends the data to an Azure endpoint and reads the output out loud.
The challenge with writing iOS shortcuts is that Apple doesn’t really have a decent way to get data out of most applications–Health is an exception here, and even though it is fiddly to get the data out and pack into JSON or CSV to add to the prompt, Shortcuts makes this quite feasible, although I still have to unlock my phone to run something that only has voice output, which is just dumb.
Language Coaching
I’m currently learning a bit of Japanese and Finnish–the first because I felt that my stab at learning Mandarin some fifteen years ago mostly failed due to lack of content (and there is certainly plenty of Japanese content), and the second because I have a suspicion the Finns are actually aliens–just kidding, I work with a lot of Nordic customers and want to understand their mindset, but Suomi is also something a college friend of mine exposed me to a long time ago, and a weirdly fascinating language to boot.
As a basis, I’m working my way through the appropriate Routledge Colloquials, which are usually great books to get started (I’ve been building up a stack of them over the years). There are MP3s available with the dialogues for each book, but as it turns out both ChatGPT (Premium) and Copilot can be decent dialog coaches (Gemini is horrible at it, the neural voices just drone on with American accents and it doesn’t understand what I say at all).
Even though I don’t really think they can help with correct pronunciation (they just run my sentences through recognition, which will not pick up on nuances), they do provide some feedback on grammar and vocabulary usage as well as decent suggestions for follow-ups, so you can go well beyond the sample dialogue from a book.
But, again, these things aren’t perfect. My Mandarin is still elementary, but I can get the gist of things enough to show you an example of a subtle screw-up:

It either got the second transcription of what I said wrong near the end, or it completely ignored the actual meaning, but I know that the right transcription should have been something along the lines of “我很高兴接受”. So, again, use with a grain of salt.
Conclusion
In short, I don’t use LLMs to perform magic. I use them as tools, and found ways to fit them into my workflows (or playtime) in ways that are generally useful to me and that spare me enough time that I can still double-check and clean up the outputs when needed.
But I also use them with full awareness of their limitations, and how the internals work which helps me leverage their strengths with the right level of expectation–which goes a long way towards making them truly useful.
The key thing is, I think, to invest gradually across several approaches and leverage the ones where you get the most return in terms of time and accuracy.
Final Note: Privacy Considerations
I have few practical concerns about privacy or data security–the work part is automatically dealt with (I’m in an Office tenant that is mostly identical to any other save for the dogfooding aspect, and there’s plenty of public material regarding how Microsoft thinks about these things), and all my personal stuff is either on-premises or run inside my own (personal) Azure AI tenant–including dedicated endpoints for the model instances I use.
On the other hand, while I do play with “regular” OpenAI, Anthropic and Gemini APIs, I don’t do it for any of my summarization, classification or writing. Make of that what you will, I guess.