 Rui Carmo
Rui CarmoAs part of my forays into LLMs and GPU compute “on the small” I’ve been playing around with the AceMagic AM18 in a few unusual ways. If you missed my initial impressions, you might want to check them out first.
Note: This is the second part of my review of the AceMagic AM18. In this post, I’ll be focusing on GPU compute and how well the AM18 performs as a role. As usual, AceMagic provided me with the AM18 for review purposes, but this piece follows my review policy.
So what do you do if you are interested in running LLMs on a mini-PC with a Ryzen 7 7840HS APU and 32GB of DDR5 RAM? Well, you chop it in half, of course. Well, not literally–I’m getting a bit ahead of myself here.
For a while now, I’ve been trying to get a handle on the state of GPU compute on small form factor machines, and how well you can run AI models on them. This is partly because I think the true potential of LLMs is in their ability to run in edge computing environments, and partly because I’m interested in how well these machines can perform as homelab servers (hence my going through several RK3588 boards).
In the case of the AM18, I was particularly interested in how well the M780 iGPU would perform in this role, and whether it would be possible to use it for LLM inference, which is still dominated by CUDA and NVIDIA hardware.
In short, the answer is “yes, but…”
Environment Setup
I tried using the Bazzite install I did on the original NVMe for some initial testing, but it soon became obvious that I was going to have a lot of problems with PyTorch and Python 3.12–I couldn’t get vLLM and other Torch-based tooling to work at all, mostly because there are no precompiled wheels of some critical dependencies for Python 3.12 yet.
Since one of my goals was also to understand how well the AM18 can perform as a compact homelab server, I decided to replace the SSD with a 1TB Lexar SSD NM790 (a Gen 4x4 drive that is faster than most of the mainboards I have) and install Proxmox as a starting point.
This made it much easier to run sandboxes and switch between complete sets of runtimes by deploying them in LXC containers and mapping /dev/dri and /dev/kfd to them, running docker alongside, or just using the host directly.
Proxmox
Installation went without a hitch–I just plugged in the same PiKVM I used to set up borg and all of my other machines (which has a Proxmox ISO on it) and installed it on the SSD using the defaults (roughly 100GB for the system and the rest of the SSD set up as LVM storage for VMs and containers):
root@am18:~# lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINTS
sr0 11:0 1 1024M 0 rom
nvme0n1 259:0 0 953.9G 0 disk
├─nvme0n1p1 259:1 0 1007K 0 part
├─nvme0n1p2 259:2 0 1G 0 part /boot/efi
└─nvme0n1p3 259:3 0 952.9G 0 part
├─pve-swap 252:0 0 8G 0 lvm [SWAP]
├─pve-root 252:1 0 96G 0 lvm /
├─pve-data_tmeta 252:2 0 8.3G 0 lvm
│ └─pve-data-tpool 252:4 0 816.2G 0 lvm
│ ├─pve-data 252:5 0 816.2G 1 lvm
│ ├─pve-vm--107--disk--0 252:6 0 160G 0 lvm
│ ├─pve-vm--208--disk--0 252:7 0 128G 0 lvm
│ └─pve-vm--109--disk--0 252:8 0 128G 0 lvm
└─pve-data_tdata 252:3 0 816.2G 0 lvm
└─pve-data-tpool 252:4 0 816.2G 0 lvm
├─pve-data 252:5 0 816.2G 1 lvm
├─pve-vm--107--disk--0 252:6 0 160G 0 lvm
├─pve-vm--208--disk--0 252:7 0 128G 0 lvm
└─pve-vm--109--disk--0 252:8 0 128G 0 lvm
Being based on Debian 12, Proxmox did the right thing and automatically installed the amdgpu kernel driver, which saved me a bit of time.
After updating the system and adding it to my Proxmox cluster, I restored a backup of one of my LXC containers, allocated 8 CPU cores to it, and did some initial testing:
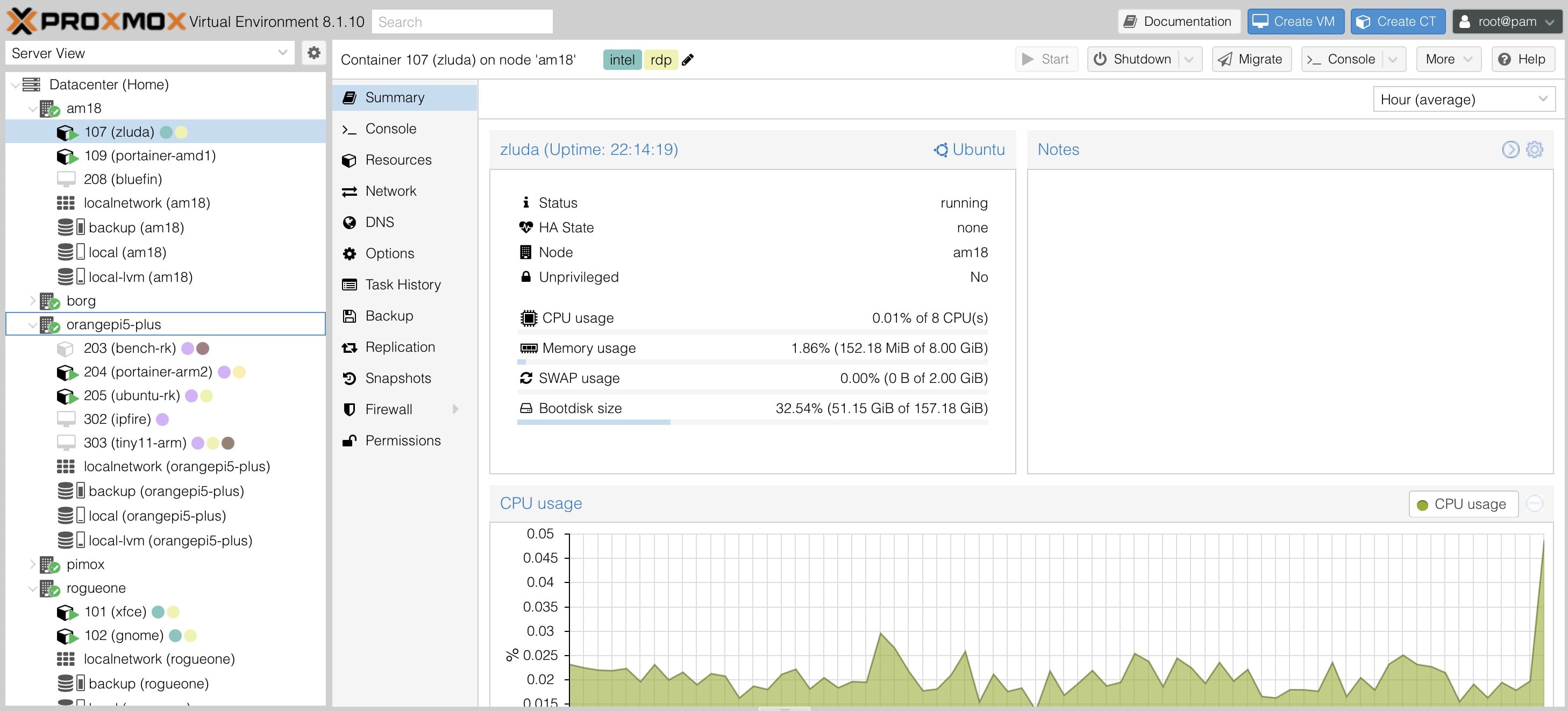
GPU-Accelerated Remote Desktop
This was the first, easy test. One of the reasons I deployed that particular Ubuntu container is that it has xorgxrdp-egfx installed–this is a GPU-aware experimental extension to xrdp which allows me to use Intel and AMD GPUs as a remote desktop accelerator.
As expected, the 7840’s iGPU performed brilliantly, and I was actually hard pressed to find things that would stress it out. Even WebGL acceleration inside Microsoft Edge worked fine (as did remote video playback):
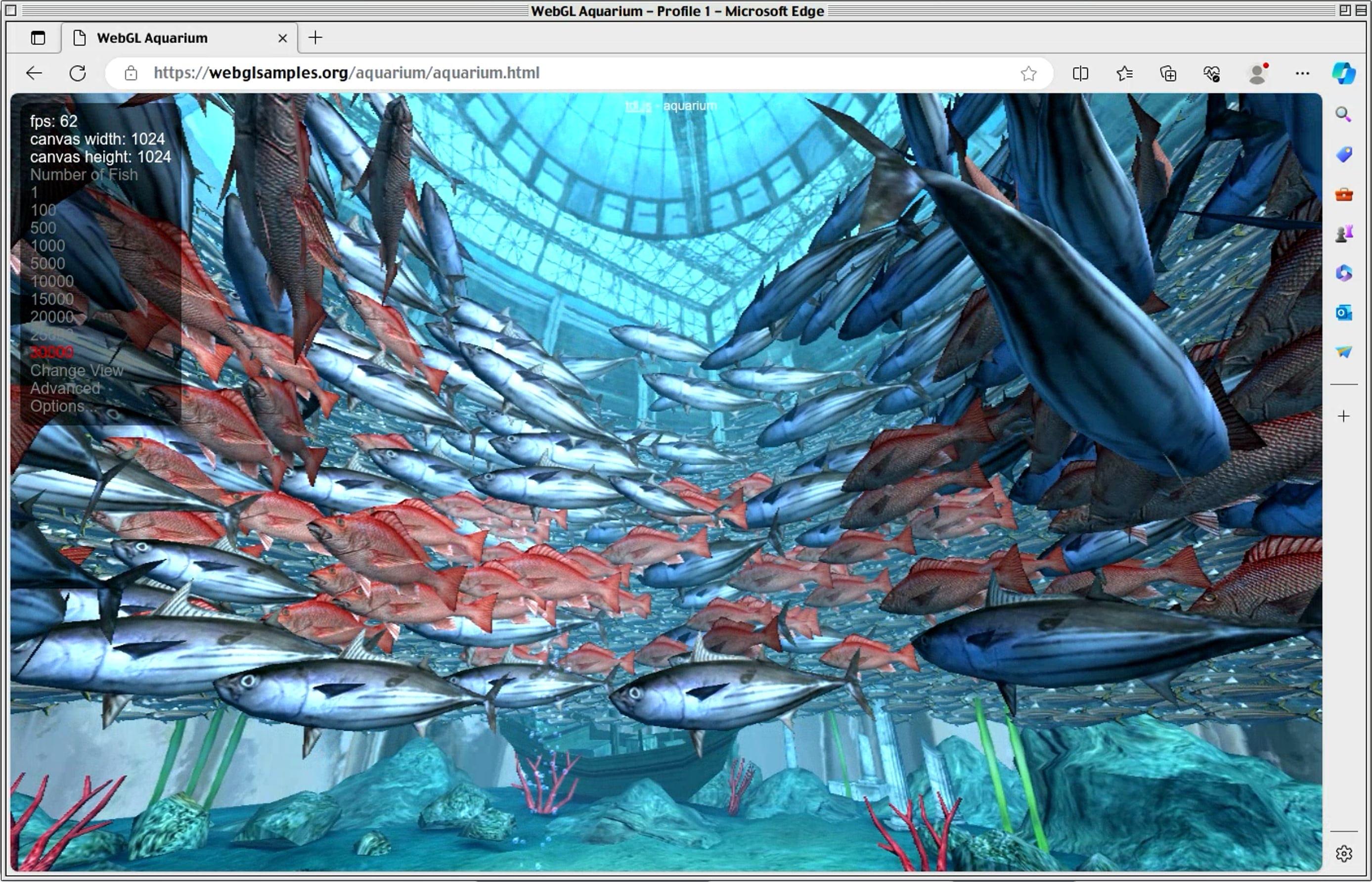
So far, so good. I then moved on to installing ollama, because it’s almost universal by now and a good test of how well the M780 might work without CUDA–or, if all else failed, how far I could get with CPU inference.
Ollama
Serendipitously, ollama now supports AMD GPUs and iGPUs directly (with some caveats), and I was able to get it to use the M780.
TL;DR
This involved:
- Reserving RAM for the iGPU in the BIOS (I set it to 16GB)
- Making sure the
amdgpukernel driver was loaded in the host - Passing through
/dev/kfdand/dev/drito the container - Setting
HSA_OVERRIDE_GFX_VERSION=11.0.0andHCC_AMDGPU_TARGETS=gfx1103in theollamaenvironment
The Long Version
But there’s a bit more to it than that So yes, the first thing I needed to do was find a way to reserve some vRAM for the iGPU, as ollama doesn’t handle dynamic allocation yet. Fortunately, the AM18’s BIOS has an option to do just that:
After setting the vRAM to 16GB, I rebooted the machine and checked that the amdgpu kernel driver was loaded, and that the M780 was detected inside the container I was running ollama in.
Then I spent hours trying to figure out how to get ollama to actually load model layers into the iGPU. The key was setting the HSA_OVERRIDE_GFX_VERSION and HCC_AMDGPU_TARGETS environment variables to 11.0.0 and gfx1103 respectively.
But static vRAM reservation is the key thing, as ollama cannot handle dynamic allocation yet (there is an issue discussing the possibility of doing that). GPU detection is still a bit flaky, but setting the HSA override seemed to fix most of it.
Performance
I then ran my usual ollama benchmark using tinyllama and dolphin-phi1:
for run in {1..10}; do echo "Why is the sky blue?" | ollama run tinyllama --verbose 2>&1 >/dev/null | grep "eval rate:"; done
Things were a bit inconsistent performance-wise, though–sometimes it would work fine, and other times it would hang for a few seconds (but metrics didn’t seem to be affected).
Update: It seems that this is due to unnecessary memory copies between the
iGPUand theCPU, since a) the BIOS pre-allocation forces it and b) even if there was a way to do dynamic allocation, the libraries used do not realize it can all be sharedRAM. This leads to duplication and, apparently, weird pauses when shuffling data back and forth. I’m delving into howiGPURAM can be allocated dynamically and tracking the relevant discussions in theollamarepo.
I pored over the logs and found nothing obvious, but validated that ollama was actually loading some layers onto the iGPU:
Device 0: AMD Radeon Graphics, compute capability 11.0, VMM: no
llm_load_tensors: ggml ctx size = 0.76 MiB
llm_load_tensors: offloading 18 repeating layers to GPU
llm_load_tensors: offloaded 18/33 layers to GPU
llm_load_tensors: ROCm0 buffer size = 14086.69 MiB
llm_load_tensors: CPU buffer size = 25215.87 MiB
I suspect the pauses were simply because ollama support for this kind of configuration is still experimental, but it led me to do quite a few more benchmarks than I had planned–first because I realized I had left the core allocation to the container at 8 cores, and then because I eventually resorted to restarting the ollama server after each run to get consistent results:
| Machine | Model | Eval Tokens/s |
|---|---|---|
AM18 16 CPU Cores+ROCm |
dolphin-phi | 40.28 |
| tinyllama | 124.02 | |
AM18 16 CPU Cores |
dolphin-phi | 28.49 |
| tinyllama | 74.36 | |
AM18 8 CPU Cores+ROCm |
dolphin-phi | 39.78 |
| tinyllama | 99.48 | |
AM18 8 CPU Cores |
dolphin-phi | 25.76 |
| tinyllama | 71.54 | |
Intel i7-6700 |
dolphin-phi | 7.57 |
| tinyllama | 16.61 | |
MacBook Pro M3 Max |
dolphin-phi | 89.64 |
| tinyllama | 185.4 | |
Orange Pi 5+ |
dolphin-phi | 4.65 |
| tinyllama | 11.3 | |
Raspberry Pi 4 |
dolphin-phi | 1.51 |
| tinyllama | 3.77 | |
VM with RTX 3060 |
dolphin-phi | 115.76 |
| tinyllama | 217.25 | |
YouYeeToo R1 |
dolphin-phi | 3.9 |
| tinyllama | 10.5 |
This time, besides including my usual RK3588 boards, I also ran the benchmarks on my RTX 3060-powered VM sandbox and my MacBook to get a sense of how well the M780 performs in comparison–in essence, it was a third of the performance of the RTX 3060 or the MacBook Pro, which gave me pause.
I went back and checked the wattage, and the AM18 peaked at 50W during these tests, quickly falling back to a bit under 10W on idle.
So this is not bad at all–it’s either substantially less power-hungry (when comparing to borg, which is where my VM sandbox lives) or a fraction of the cost (when comparing to the MacBook Pro), while still delivering usable performance (at least for simple models).
Running Bigger Models
I then pared down the test universe a bit tried mistral (which is twice the size of dolphin-phi, and which I could never fit into an SBC). The 7840 was still able to run it at a very usable speed, but it was starting to become obvious that even with DDR5 memory, this AMD chip doesn’t have the kind of performance required to compete in the big leagues:
| Machine | Model | Eval Tokens/s |
|---|---|---|
AM18 16 Cores+ROCm |
codellama | 19.3 |
| llama2-uncensored | 19.71 | |
| mistral | 19.62 | |
MacBook Pro M3 Max |
codellama | 54.14 |
| llama2-uncensored | 54.62 | |
| mistral | 51.43 |
Still, I don’t think it was a bad showing. You’ll notice that in the table above, and for good measure, I also threw in llama2-uncensored and codellama2.
mixtral (which is, in turn, almost three times the size of the others) was a no-go, since it wouldn’t fit into the 16GB RAM (at least without quantization, and ollama actually crashed when trying to load the model into the iGPU).
Considering the weird environment and constraints, I found it fascinating that most of these worked, since I have become too used to the limitations of ARM chips in this regard.
Bolstered by this success, I then went and got more exotic models to work (some I had to convert to GGUF). I also tried quantizing a few, but the results were again inconsistent. Sometimes the 7840 was able to run them, but the performance was abysmal.
But I had other things to try, so I moved on.
ZLUDA
The above was actually just a couple of days of testing–my original intent was to test ZLUDA (a project that was actually funded by AMD and aims to provide a CUDA-like interface for AMD GPUs).
However, over the past few weeks I’ve had less than stellar results with it. Just getting PyTorch to acknowledge it exists has been a major chore, and vLLM doesn’t seem to work with it at all:
export LD_LIBRARY_PATH="/home/me/Development/zluda;$LD_LIBRARY_PATH"
# This prompted me to install accelerate and bitsandbytes but failed to detect them
TRUST_REMOTE_CODE=True openllm start microsoft/phi-2 --quantize int8
# This fails miserably because torch insists on trying to load the NVIDIA userspace libraries via torch._C._cuda_init()
RUST_REMOTE_CODE=True openllm start microsoft/phi-2 --backend=vllm
Also, VLLM required safetensors models. Even with a nominal 16GB of “vRAM” reserved for the iGPU, this got resource-intensive really fast (which is why I went back to smaller models in the examples above).
Then Easter Break came, and I had to put a chunk of this on hold–but I hope to get it to work eventually, because the potential is there. The 7840 is a very capable chip, and the performance with ollama hints at what could be possible with a bit more work.
More Conventional GPU Workloads
As a server, the AM18 is a tiny little RGB rainbow-hued beast of a machine. For instance, I have been running a Bluefin VM on it for a few weeks now, and with VirtioGL enabled, it’s been able to handle everything I’ve thrown at it:
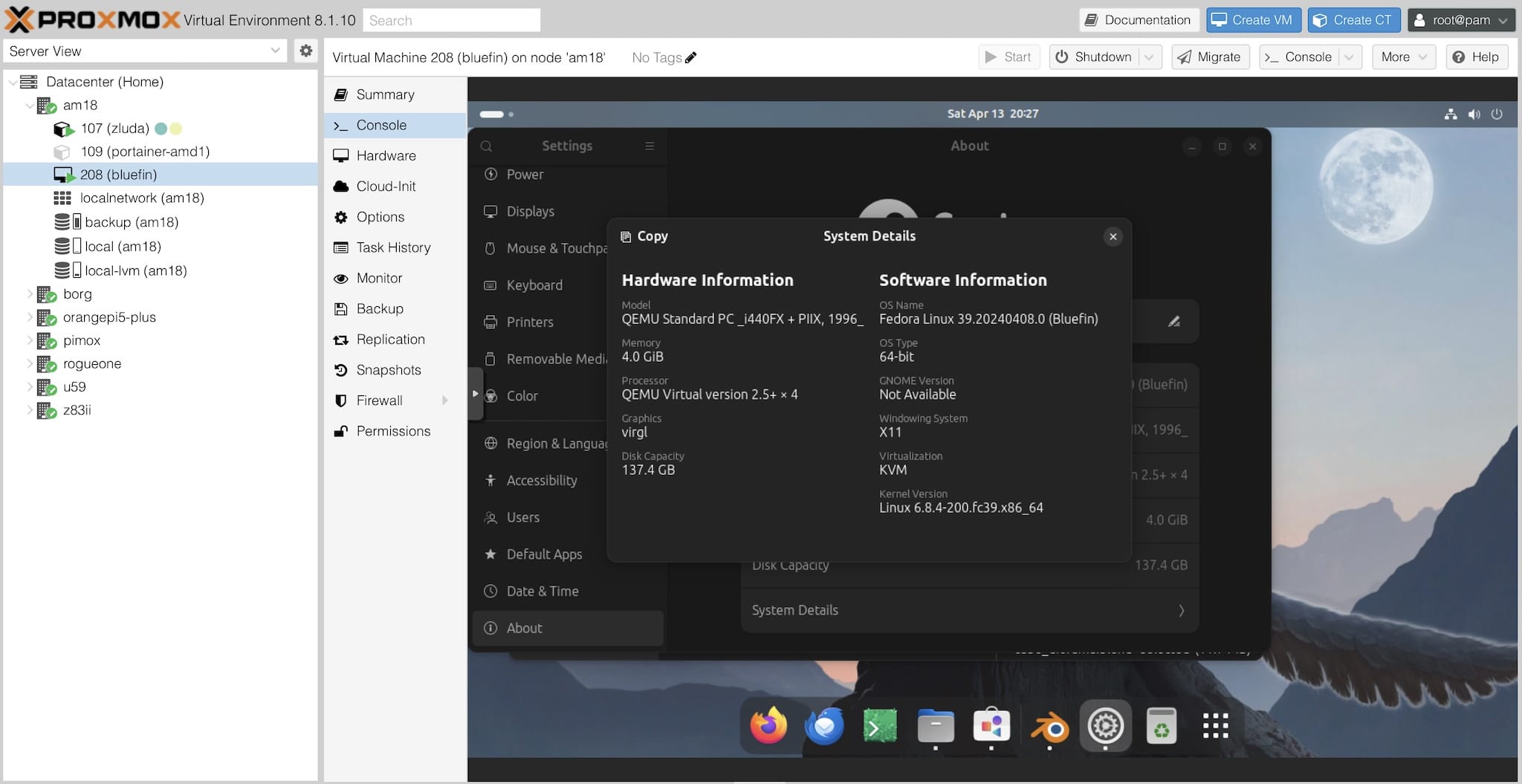
I briefly enabled IOMMU and tried passing through the M780 to the VM, but I couldn’t get it to work well–I lost console output, for starters, which was a bit annoying, so I reverted that. But I don’t see a need for it as long as virtio works (even for Windows VMs).
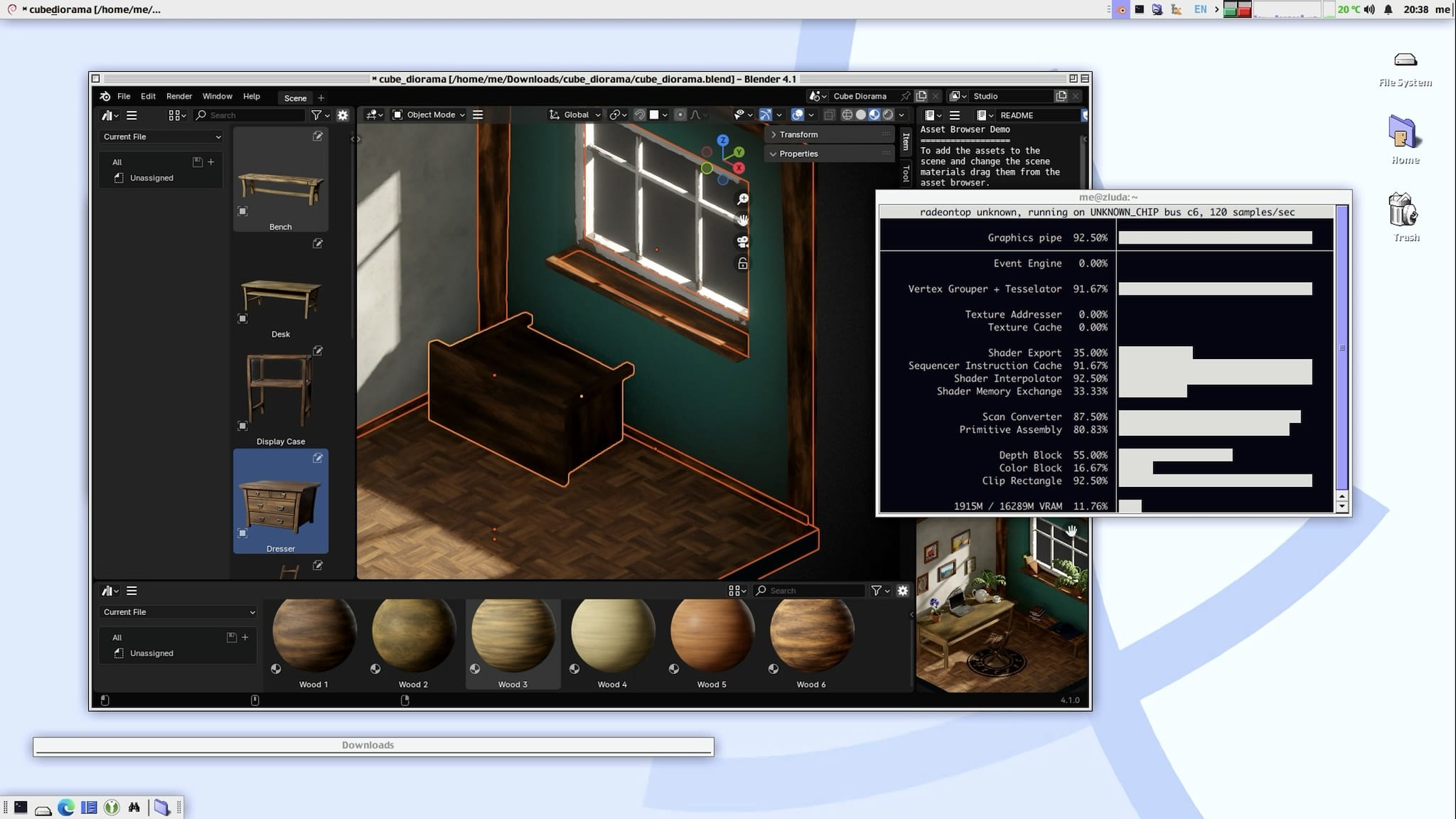
Looping back to remote desktops, running Blender inside LXC worked spectacularly well, although it didn’t quite detect the M780 – it was being used for UI rendering (radeontop showed plenty of activity), but Cycles didn’t seem to detect it:
I’ve also been running a few Docker containers on it–I moved my test Jellyfin server to it, and it mostly worked, except that the particular AMD-tuned ffmpeg build that Jellyfin uses doesn’t seem to like the M780 and kept refusing to transcode some videos.
And, of course, CPU workloads are a breeze–like all AMD CPUs of this class, multi-threading performance was outstanding–but that’s not why I was interested in the AM18.
Conclusion
Just as I pointed out in my initial review, the AceMagic AM18 is a very capable machine, although the lack of storage expansion options is a bit of a downer. But as a homelab server for a couple of VMs and, say, a few dozen LXC or Docker containers, it’s a very good choice, especially if you keep in mind the low power consumption–and I kept having to remind myself that I had effectively halved its amount of RAM for my LLM testing.
As a GPU compute platform, it’s a bit of a mixed bag. The M780 is a very capable iGPU, but it’s not quite there yet for LLM inference3–although it’s tantalizingly close, and I expect 8xxx series AMD chips to pick up on this.
On either case, AMD iGPUs need better Linux support, and we’re not out of the CUDA valley, although I suspect that with a bit more work on the part of the ollama team, a box like the AM18 could be a very good choice for running various kinds of ML at remote sites (and a cost effective way to run targeted LLM models).
I’ll keep an eye on this, and I hope to have more to report in the future. In the meantime, I’ll try to test ZLUDA a bit more and see if I can get it to work with vLLM.
Watch this space.
-
And yes, I know these models aren’t ideal–but they scale down to low-end machines and seem to be acceptable proxies for the kind of special purpose model I expect to run in an edge computing scenario. ↩︎
-
I changed the prompt to “Write a Python function that generates the Fibonacci sequence” for this one, because I was getting tired of reading about Rayleigh scattering. ↩︎
-
In retrospect I should have tried to measure
iGPUmemory bandwidth, but right now the software side of things is still too brittle to make that a priority. ↩︎