 Rui Carmo
Rui CarmoThe weather is… infuriatingly tropical, but tolerable (we’re used to the heat this time of year, but the dampness is relatively new), and shifting all my morning meetings to my standing desk has markedly improved (but not fully healed) my back, so it was a relatively OK week.
Other than it being the last fiscal month at work, that is–my thresholds for patience have become somewhat elastic over the years, but it’s still a busy part of the year.
That, and the ongoing industry madness pushed me into another reassessment of how I have been spending my time, and I decided to go back to more hands-on work.
The Photogrammetry Detour
Since I have a bunch of CAD work to do, I tried my hand at photogrammetry over the week to see if I could speed up creating SBC board cases:
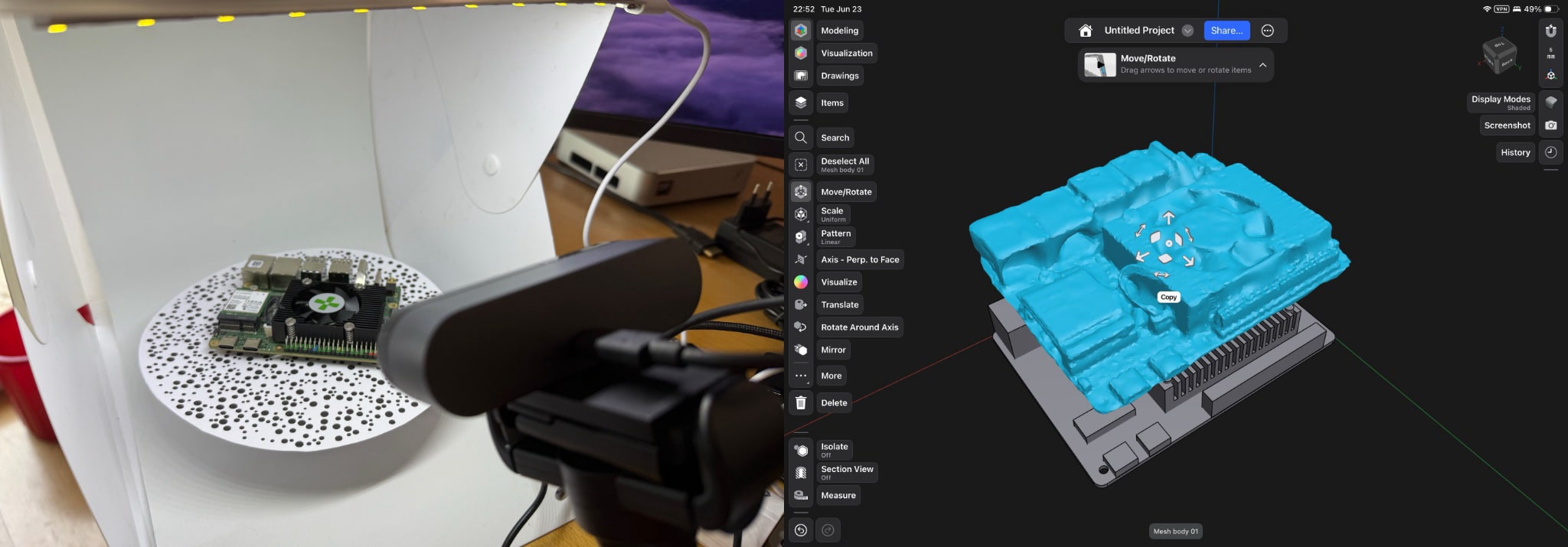
The main conclusion so far is that although the photogrammetry process itself worked (and I could probably write a fairly detailed post about the C++ libraries I used and how I automated the process), even with 4K inputs and a few passes at refining the mesh it’s just not accurate enough to do what I need, partially because the BRIO 4K’s autofocus is a bit of a wash:

Now, that is tweakable, but the process is still a bit too manual and error-prone to be worth it for me.
In comparison, flipping the script on my previous attempts at using AI and just feeding photos to piclaw has been working stupendously well, and even if the dimensions are off, I can fix them easily in CAD once I have a STEP file:

As much as I would love to get my hands on a 3D scanner, I suspect this will be my go-to approach from here on out–although I’m currently investigating if I can re-use the image-processing pipeline to guide the model:

Tiny Local Models
Before shifting back to more pragmatic pursuits, I still “finished” a few AI-related things, mostly related to Gemma 4.
In short, after some messing around with QAT and MTP weights, I have finally gotten a reasonably smart and speedy version of Gemma4-E4B to run on my RTX3060 at nearly 90 tok/s, but…
It still isn’t as smart (or fast) as I would like for running my agents, and the context window is much smaller than what I ordinarily consider usable. Even for automating “if this (and maybe that) then (this other arbitrary set of things)” workflows… It just barely qualifies.
I might poke at it a bit more, but the core issues I had during my K3 review still stand: both context and capabilities of this kind of model are still far below what I need for regular use (piclaw can use it, but the results are always frustrating), and SOTA models are still much, much more effective than anything else.
Recent price hikes have put me off the notion of ever getting good enough hardware to run anything useful locally unless I win the lottery or something, so this might be a dead end for the rest of the year.
RSS, With Less Baggage
I also went after my daily news intake–the news is bad enough as it is, but I can at least try to make it less stressful to consume.
Back when I was moving away from Feedly to FreshRSS I briefly considered Miniflux but discarded it because I thought it lacked features I ended up never using, so this week I decided to fork it, replace its PostgreSQL database with SQLite and create something even more minimalist I dubbed picoflux – which seems to work just fine with Reeder and takes up a whopping… 70MB of RAM when running as a dedicated service.
That’s far less than the PHP and database baggage that FreshRSS brought, and it let me downsize the (already) tiny Azure VM I run “insecure” services in to half the capacity, so that’s a win right there.
Migration was, as usual, another opportunity to prune/fix stale feeds, but completely uneventful other than NetNewsWire not having support for Miniflux–which is not a problem since I am still using Reeder, but said support seems to be coming, and if my UX gripes (which revolve around scrolling and overly garish iconography) get fixed, I might well switch to it.
Going Back To Raw Feeds
After three years of experimentation and around nine months of daily use, I am bringing my feed summarization experiment to a close, for the following reasons:
- My reading habits and schedule changed to a point where I was not really reading all of the bulletins (especially the noon and evening ones) and they just piled up.
- The bulletin structure itself, despite being great for a few of the feeds I wanted to keep a cursory eye on, was just not good enough to surface important news.
- Following the links inside bulletins was a bit fiddly (they were too small a target to pick out from a page of text, and turning the entire summary into a hyperlink to “fix” that just didn’t work inside any RSS reader).
- I realized that my brain is just better at scanning hundreds of headlines and ranking them as they scroll past on the iPad.
- It is another service to run and maintain, and I wanted to focus on other things.
To be fair, it has had exactly zero code changes other than a couple of cosmetic fixes and the LLM API costs were under $5/month, but asking myself “why” didn’t surface a lot of value.
That is not to say that the summaries were not valuable, but it’s just easier to prune noisy, spammy feeds. I have also considered using the summaries to feed a “smarter” agent that would notify me of “interesting” news, but my interests are so wide (and shift priorities so often) that it would be tough to get consistent output out of that, too.
I suspect I will circle back to this with a fresh point of view (and I have been thinking about how to refactor it into a pure functions/workers construct), but for now it’s just easier to wind it down for the holidays.
sashimi Soak Testing
I picked up sashimi (the Go port of this site’s static generator) again this week, and after running the numbers on visual rendering parity (which piclaw and Codex helped me with by generating some nice visual diffs), it is now at a point where it can render the entire site with pretty much 100% fidelity to the current renderer–except for a few corner cases, and with some bits already looking better.
It is blazingly fast, and incremental rendering is ridiculously fast, but more to the point it’s finally good enough to run alongside the main engine, generating a complete staging site entirely inside GitHub Actions (with a somewhat complex but quite fun set of cascading, low-impact actions) that do the required incremental/partial rendering in seconds instead of several minutes.
It’s probably interesting enough to deserve a dedicated write-up, and that will happen after a couple weeks’ soak time. I’ve already done a bunch of “live” testing, but I’m sure regular posting will surface more things to fix.