 Rui Carmo
Rui CarmoLike everybody else on the Internet, I routinely feel overwhelmed by the volume of information I “have” to keep track of.
Over the years I’ve evolved a set of strategies to focus on what is useful to me without wasting time–and, as with everything else I do, I sort of over-engineered that over the past year or so into a rather complex pipeline that I thought I’d share here.
Social Networking Is Still Mostly Just Noise
Part of the problem is social networks, of course. I have actually decided to “go back” to X/Twitter this year because Bluesky is going nowhere, Threads feels like Zoolander territory and empty of most rational thought and even though Mastodon has an amazingly high signal-to-noise ratio, most people in tech I want to follow or interact with are still on X, and there is no real way around it.
But most of that is just noise these days, so despite accepting I will still have to hop through two or three apps over breakfast to “catch up”, I have been taking steps to greatly minimize the overhead of keeping track of truly important things–decent writing and technical content.
And most of that still lives in blog posts. Not Medium, not Substack, but actual blogs from people whose writing I want to keep track of. Yet, there are still so many of them…
RSS Is Still Very Much Alive
Even after Google killed off Reader, I (and many others) kept reading (and publishing) RSS/Atom feeds, and even if companies and mass media turned to social networks to hawk their wares, my reading habits haven’t changed.
It’s been over a decade, and I’ve kept reading pretty much everything through RSS, handpicking apps for various platforms and having the read state kept in sync through Feedly.
RSS remains the best, most noise-free way to keep track of most things I care about, and at one point I peaked at 300+ feeds.
But the reason it’s been working out for me is not just having a single source of truth, or the apps themselves–it’s the way that I approached having multiple hundreds of new items (sometimes thousands) every morning and whittling everything down to a few meaningful things to read every day.
Discipline
The first step is feed curation, and since I don’t subscribe to many overly spammy sites (although I do want to keep track of some news) and I have zeroed in on a small but interesting set of individuals whose blogs I read, that’s helped a lot.
But I still have 200+ feeds subscribed, and even if individuals don’t post every day (or week, or month–well, except for John Scalzi), I still have to keep track of current news… which is a bit of a problem these days.
Impending Doom is a Great Incentive to Focus
Thanks to the pandemic, doomscrolling, and the overbearing impact of US politics in our current timeline, I decided to cut down drastically and only read news three times a day.
So I naturally gravitated to a set of requirements that boiled down to: a) wanting to keep track of individual blogs as-is, and b) wanting “bulletins” of high-volume feeds summarized, with items grouped by topic and “sent” to me early morning, lunchtime and post-work:
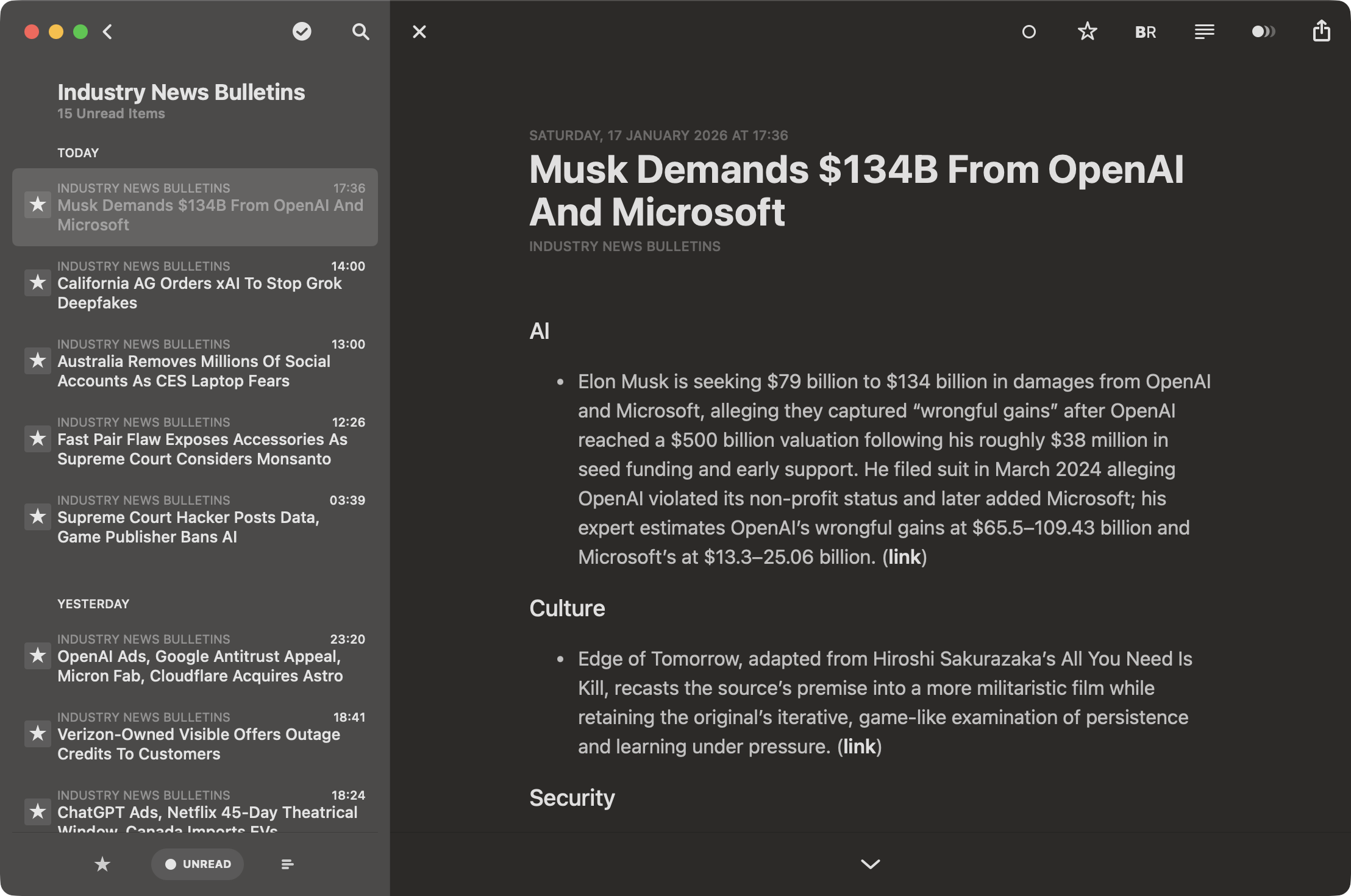
Each bulletin is the aggregation of five or six feeds (which themselves often come from aggregators), but some of those feeds are news sites (think Engadget, The Verge and a few local newspapers) that live and breathe by publishing dozens of snippets a day (like MacRumors, which is notorious for breaking down Apple event coverage into a dozen small posts per event), so the original feeds can be extremely fatiguing to read.
By clumping them into bulletins, I get enough variety per bulletin to keep things interesting, and am able to go through chunks of 20-30 summaries at a time. In busy news days I’ll get more than one bulletin per time slot, but that’s fine.
Either way, this process means I get around 15 bulletins to read every day total instead of 200 or so individual items, and I’ve added summary grouping and recurring news detection so that I can zero in on what I care about and skip topics I am not currently interested in–very much like a newspaper, in fact.
Going Full Rube Goldberg
The fun part is that this started out as a pretty simple, very hackish Node-RED flow.
As with everything Node-RED, it was an awesome interactive prototype: I could build custom fetchers with great ease and wire them in on the fly, and adding extra steps to label, batch summarize and publish the results was pretty much trivial.
The ugly part was maintainability and debugging, so one day back when I was starting to play with Claude (which I quickly tuned out, by the way–I am much more a fan of GPT-5.x’s sober, emoji-free replies and sharper focus), on a whim I decided to paste in a simple version of JSON flow and ask it for a Python version–which, to my amazement, it did, in rather exciting detail:
# From the first commit back in June 2025
fetcher.py | 853 ++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
models.py | 654 ++++++++++++++++++++++++++++++++++++++++++++
summarizer.py | 595 ++++++++++++++++++++++++++++++++++++++++
That worked so well I decided to re-architect it from scratch and turn it into a proper pipeline in the spirit of my old newsfeed corpus project. I had already sorted out most of the sqlite schema, so reworking the fetcher around aiohttp and following my usual approach at building services was just the accretion and iteration process, which eventually came to… this:

The diagram might seem a bit daunting, but it’s actually pretty consistent with most of my previous approaches to the problem, and aligns with the overall module structure:
workers/
├── fetcher/ # 429-compliant fetcher
│ ├── core.py
│ ├── http_fetch.py
│ ├── entries.py
│ └── schedule.py
├── summarizer/ # gpt-4o-mini (later gpt-5-mini)
│ └── core.py
├── publisher/ # hacky templating
│ ├── core.py
│ ├── html_renderer.py
│ ├── rss_builder.py
│ └── merge.py
└── uploader/ # Azure Storage
└── client.py
I set things up so that workers can run as completely independent asyncio tasks. Since then it’s been mostly about refining the processing and publishing logic, as well as a few tweaks to complement the fact that I decided to move from Feedly to self-hosted FreshRSS and gained more reliable feed checking in the process.
Fetching
Like I mentioned above, this isn’t my first rodeo doing massive feed fetching and normalization, but a fun fact is that I followed Rachel’s recommendations regarding polling, ETag handling, back-offs and 429 result code handling to the letter… and still got blocked.
I have absolutely no idea why, since I only poll her site every 24 hours and use the exact same freshness, result code handling and fallback logic for all feeds. I haven’t bothered trying to “fix it”, though.
But for everything else, the fetcher is a fairly standard aiohttp-based fetcher that handles feed fetching, parsing (via feedparser), and storing new entries in sqlite.
Normalizing To Full Text
One of the reasons most regular folk don’t use RSS is that over time many commercial sites have pared down their RSS feeds so much to the point that they are almost useless.
I have no idea why individual bloggers (especially people who for some reason still run WordPress or another ancient contraption of that ilk) don’t publish proper full text feeds.
News sites obviously want to drive pageviews for advertising, but the amount of tech folk who run personal blogs and have one-line summary feeds is frustrating–and doubly so when they have both the skills and the control over their publishing stack. I have always made it a point of publishing full text feeds myself.
My pipeline thus tries to normalize every feed in various ways:
- It runs the original page through
readabilityandmarkdownifyfor summaries (since in that case I don’t really care about the full content just yet). - It tries to generate a normalized readable text feed for pass-through feeds that I don’t want summarized but that I want the original full text for.
- If that fails for some reason, FreshRSS has its own feed/page scraping mechanisms that I can use as a fallback and still get most of the original page content.
The summarizer also has a couple of special cases it handles separately, largely because for Hacker News I go and fetch the original links (I ignore the comments, at least for now), check if they are GitHub or PDF links, and run them through custom extractors.
Social Feeds (i.e., Mastodon)
X/Twitter has tried to paywall its API to oblivion and I refuse to either pay for that or build my own scraper, so over the past year I have made do with curated Mastodon lists and turning them into RSS–again, a simple Node-RED hack that just kept on giving, and I incorporated that into my pipeline.
Right now that is a simple “pass-through” private feed generator, but I’ve been considering folding them into the main pipeline since they can be a bit noisy.
Generating Summaries
The next step for most feeds is summarization, which I do in batches to save on token usage. Right now I am using gpt-5-mini to summarize items in batches, and the output is a set of (summary, topic) pairs that goes into sqlite.
As an aside, my old “You are a news editor at the Economist” joke prompt is still very effective, and working remarkably well in terms of tone and conciseness, so I’ve stuck to it for the whole time.
Clustering and Merging Stories
This is where I spent a long time tuning the system, since one of the problems of aggregating across multiple news sources is that you’ll often get essentially the same story published across three or four sites (often more as individual bloggers comment upon breaking news).
But to get there, you first need to figure out how to group:
- Named Entity Recognition (which loses effectiveness with summaries). I had a go at doing very simple regex-based detection to avoid bundling a full BERT model, but it hardly moved the needle.
- TF-IDF and KMeans (which requires a fair bit of computation).
- Vector embeddings (which would require either sizable compute, storing local models, or additional API calls).
The one that I’ve mostly settled on is simhash, which I like to think of as the poor man’s vector embedding approach and has a number of advantages:
- It requires only minor stopword cleanups.
- It’s very high performance, even on slow CPUs.
- I can use very fast standard distance rankings instead of going all out on cosine similarities.
By combining it with sqlite’s BM25 indexing, I managed to get good enough duplicate detection across summaries to significantly reduce duplication inside the same bulletin, although it does have a small percentage of false positives.
And, incidentally, that “Economist” summarization prompt also seems to help since it sort of enforces a bit more uniformity in summary wording and general structure.
Once clusters are identified, they’re run through a separate summarization prompt, and the end result looks like this:
The Federal Communications Commission added foreign-made drones and qualifying components to its “Covered List,” barring FCC approval and effectively blocking imports of new models it deems an unacceptable national-security risk—citing vulnerabilities in data transmission, communications, flight controllers, navigation systems, batteries and motors. The rule targets future models (not devices already approved or owned) and allows the Department of Defense or Department of Homeland Security to grant specific exemptions. Major manufacturers such as DJI said they were disappointed. (1; 2; 3)
I’ve been trying to “improve” upon simhash with my own ONNX-based embedding model and sqlite-vec, but so far I’m not really happy with either accuracy or bloat (ONNX still means a bunch more dependencies, plus bundling a model with the code).
But simhash has just kept on giving in terms of both performance and accuracy, and I can live with the odd false positive.
Recurring Coverage
If you remember how real life newspapers used to work, breaking news would gradually drop from the front page to someplace inside the fold–they’d still get coverage and follow-ups, but you’d only read that if you were interested in following up.
simhash is also playing an important role here, since what I do is take each summary and do a retrospective check for similar past summaries–if the same news was covered recently, I classify those new summaries as “Recurring Coverage” and group them all together at the end of the bulletin, which is a convenient place for me to skip them altogether after a quick glance.
This is especially useful for things that tend to be covered multiple times over several days–Apple launches, industry events, etc.
A great example was CES coverage, which can drive news sites completely bananas and inevitably results in the same news popping up over several days across most of your feeds:

Addendum: Tor
I decided to add tor to my pipeline as a proxy for fetching selected feeds both in my custom fetcher and in FreshRSS, simply because some stupid newspapers try to geo-lock their content.
I live in Portugal (and like to keep track of local news in a couple more places), but my fetcher runs in either Amsterdam or the US (depending on where compute is cheaper on a monthly basis), so that turned out to be a kludgey necessity.
Joining the Fun
If you’ve read this far, I currently have a somewhat stable version up on GitHub that I occasionally sync with my private repository. It’s still a bit rough around the edges, but if you’re interested in building something similar, feel free to check it out.