 Rui Carmo
Rui CarmoDespite being unable to code much these past few weeks, I have been mulling my RSS intake yet again, and finally had the time to put most of it together in a coherent article.
Some Background
Regular readers will know that I have been using newspipe for years now, and that handling RSS has been part of my never-ending quest for easier information management for even longer, so I thought I’d post a brief summary of the current situation.
Over the past couple of years, I eventually got to the point where I would have something like 200-odd feeds subscribed and yet only 60 or so new items a day - the magic resided in a companion script that did Bayesian classification of that veritable firehose of data and pared it down to the bare essentials1:
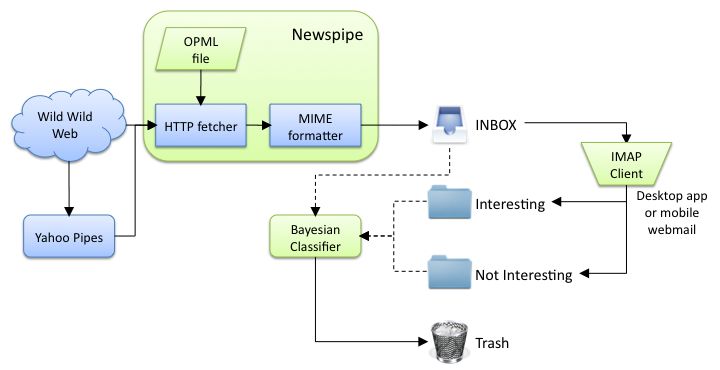
Every evening I would simply fire up Mail.app, hop into my News inbox, and make short work of it with a couple of Mail Act-On actions: one to train stuff as interesting and another to tell the classifier to start ignoring that kind of pieces.
Plus I’d use the standard IMAP message flags to highlight stuff worth following up on (re-reading, researching, or writing about).
And it worked remarkably well after the first couple of weeks of training - every now and then I would rummage about in the Trash to see if I’d missed anything of consequence (and in the early days it did), re-classify it as interesting, clear out the training folders, and archive the stuff on inbox that I believed to be worthwhile saving for posterity, but it was remarkably maintenance-free.
Keeping Score
It was not, however, without its disadvantages:
| Aspect | Pros | Cons |
|---|---|---|
| Filtering | Bayesian filtering is vastly superior to any keyword-based processing | Eats up CPU resources on the server. Might filter out interesting stuff. Trouble with multilingual posts. |
| Archival | Images are stored alongside text. Anything on IMAP can be backed up or indexed with Spotlight. |
Takes up disk space. |
| Sharing | Just forward the resulting e-mail, complete with inline images - friends do not need to have (or know anything about) RSS. | Never really found any. |
| Mobility | Anything with an IMAP client will work. Allows for offline reading. |
Not all IMAP clients are good enough (most mobile clients aren’t). Needed to roll out and maintain my own micro-webmail UI. |
| Maintainability | Full control. If it broke, they were my pieces to keep. | Had to edit OPML by hand, manage cron jobs, maintain what were essentially three different code bases (and newspipe itself is also in dire need of an overhaul). |
As it turns out, the biggest thing for me was maintaining the mobile UI for it (a very early version of which is still available on Sourceforge in the contrib directory), simply because it relies a lot on PHP’s image resizing features, which in turn required specific server-side tweaking.
And with my move to Yaki, my interest in coding (or maintaining) PHP code waned, and the prospect of re-coding it in Python didn’t help - despite it not being any more complex than some of the other stuff I did in Yaki, I had other priorities.
On Cloud Nine
So I have recently switched to Google Reader as my main UI for reading feeds, and relegated newspipe to an archival role:
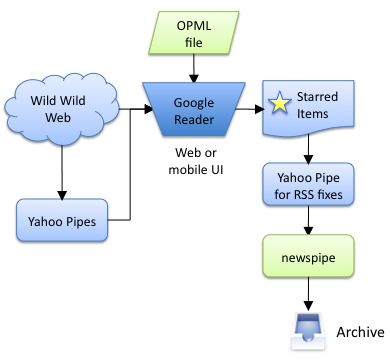
It is, on the whole, a lot simpler, but you will notice that I had to build a Yahoo pipe to cope with some idiosyncrasies of Google Reader’s RSS generation.
But that’s not the whole story. If I were to fill out a similar table regarding this approach, the result would always come out like so:
| Aspect | Pros | Cons |
|---|---|---|
| Filtering | None found yet. | Both Reader and Pipes are unable to do more than basic keyword matches, which are pretty much useless. |
| Archival | Everything gets archived on the Google cloud (and I keep a local copy). I can search through all my RSS items from anywhere. |
Getting meaningful search results is, oddly, much harder, since I get a lot more hits. |
| Sharing | One-key sharing to a selected group of people, e-mailing of simplified items. | Sending a complete message with inline images attached still requires me to dip into my archive. |
| Mobility | Anything with a decent browser will work. No need to maintain my own front-end. |
No way to have offline reading (unless they find a way to stuff Google Gears onto a phone). |
| Maintainability | Very easy to add/remove subscriptions. No need to tweak the internals of anything. |
Pipes get extremely complex after a while and there is a diminishing return on tweaking them further. |
Tangled Pipes
Regarding the last cell above (i.e., the diminishing return on tweaking pipes further), it’s a direct consequence of not having any way to add Bayesian classification (and worse, training) to this setup - which means that you end up with pipes that look like this:
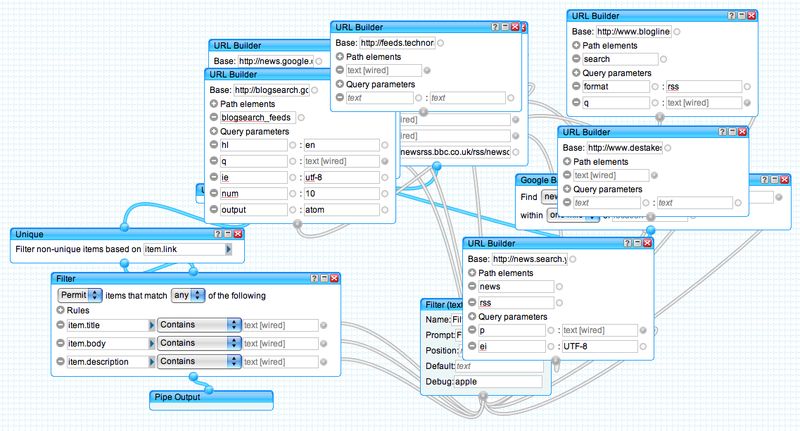
And this is not the most complex one - there are simpler ones devoted solely to merging planets and removing articles from specific authors and suchlike, but out of the 12 in all that I use, I’d say it’s about the one with “average” complexity.
But I’m fast arriving at the conclusion that this setup isn’t good enough - the UI is better in some aspects, sure, but I am still getting something like 100 new items a day - and most of them aren’t anywhere near as interesting as the kind of stuff my classifier let through.
So I’m trying to figure out a way to get classification back into the picture, and most likely as a filter to whatever Google takes as input. Right now I’m looking at something as simple as creating a simple RSS proxy that I could use as follows:
http://my.filter.box/bayes/http://original.feed.url
…and which would take its training from my starred and shared items in Google Reader. It’s doable, doesn’t require a whole lot of coding (I’ve gone from concept to basic testing in half an hour), but raises other issues, such as maintainability, introducing a single point of failure into the system, etc., etc.
And I haven’t completely given up on newspipe yet, since if I were to, say, get one of the new iPod Touches with a decent e-mail client, I’d be able to grab all my reading material over Wi-Fi before my daily commute and read it with a pretty damn decent e-mail client2.
The Desktop Aggregator Approach
A final word on NetNewsWire, NewsGator and the like: as much as I like NetNewsWire, the experience I had using their syncing stuff across one of my Macs, my Windows laptop and a few phones wasn’t that good, mostly for the following reasons:
- Their NewsGator Go! Java application feels awkward at best, and does not fit in with the UI of any of the devices I tried (a Nokia device, a BlackBerry and a SonyEricsson one). It does have a few strong points (it goes out of its way to save bandwidth, for instance, and makes sensible use of the directional pad), but looks and overall usability aren’t part of that list.
- I’ve noticed that NewsGator also allows for e-mail access - but they do it via POP3 (something that doesn’t work for me), and I don’t think they include inline images as MIME parts.
- I have only tried their web UI once, and although I liked the feature set, Google Reader wins hands down in terms of raw speed (and the keyboard shortcuts make it vastly more usable than anything else out there for me).
- I don’t like the idea of using a specific application for reading my feeds. I want something standard and generic, like a browser or a mail client.
On that last count, I should probably also add that I don’t believe in things like site-specific browsers. The only concession I make to that particular trend is that I use Camino for accessing Google Reader (mostly out of habit, since there was a time when it did not work properly with Safari).
Update: There is, however, one thing that NewsGator does better than Google Reader: their iPhone UI is much better than Google’s, using Ajax extensively. Google has devoted noticeably more effort to Gmail than to Google Reader in that regard - if Google Reader borrowed Gmail’s UI, it would probably garner a lot more iPhone users.
I also find it convenient to have a separate cookie jar for my news reading sessions and my browsing/work sessions, something that is also tied to my bouts of web development - repeatedly resetting Safari’s cache and the like while reading documentation requires you to have a secondary browser around.
So no, there is no perfect solution. But I hope to be able to keep tweaking mine until it’s close enough.
The trade-off is, of course, time taken to do the actual tweaks vs. quality of results (and, indirectly, time spent or wasted reading the results). It’s not easy, and it’s not getting easier…
-
The diagrams in this article were drawn in PowerPoint 2008. I’ll be resuming my review of Office 2008 soon, but I can let you know right away that the updated drawing tools are pretty damn good for this sort of thing. ↩︎
-
That, sadly, still does not allow for flagging messages for follow-up (or even create to-dos from messages), the second major put-off for me right after the lack of direct .Mac syncing. But that’s for another piece further down the road. ↩︎