 Rui Carmo
Rui CarmoI’m going back to the office tomorrow after some leisurely travel, and besides sunning, wading in the surf looking for seashells and other real life niceties, I managed to do some “real” thinking and a fair bit of hacking.
Gadgets are Becoming Wasteful
My earlier rant about hardware needs a little follow-up – which I’ll get to eventually – but it bears noting that I’ve thought a bit more along those lines and now believe we’re doing smartphones all wrong. I’m drafting a longer post on this topic, but given that we’re going to be sucked headlong into a whole week of Apple hype, there’s something I deem worth mentioning right away:
The big, hulking behemoths that most smartphone vendors are pushing these days feel more like a misplaced, wasteful and anti-ergonomical quest for The One Device than truly usable tools. By trying to design them to do everything, we’re not actually achieving anything of consequence, and quite likely harming ourselves in the process.
In a nutshell, I’m becoming (again) rather partial toward smaller, less pretentious devices1 that do less and free me to try to achieve more.
Also along those lines, I’m rather skeptical of the current smartwatch craze. I gladly stopped wearing perennial self-winding, zero-maintenance wristwatches well over a decade ago and see no point in going back to wearing a ephemeral, bulky ego-boosting piece of uninformative junk that requires charging every evening2.
Comfort Zone? What’s That?
As it turned out, I spent very little time coding – but besides yesterday’s hack and other Python stuff I managed to dabble a bit in Clojure and Go to get an updated feel for either language. We have a little benchmark game going on at the office, so I sumbitted and tweaked entries for those (spoiler: Go wasn’t suited for that specific task).
I’ll be writing about that as well (I’ve already made up my mind as to what role either language will play in my near future), but what bears noting is that I’ve dipped into both communities and gathered enough reading material to last me at least a couple of months, some of which I’ve been skimming in the evenings interspersed with my (as usual, pretty intensive) book reading.
Less is More
But speaking of skimming, one of the things I did to decrease cognitive overhead while keeping track of news was to add a simple (and extremely naïve) text summariser to rss2imap that tacks the three “most relevant” sentences atop each item like so:
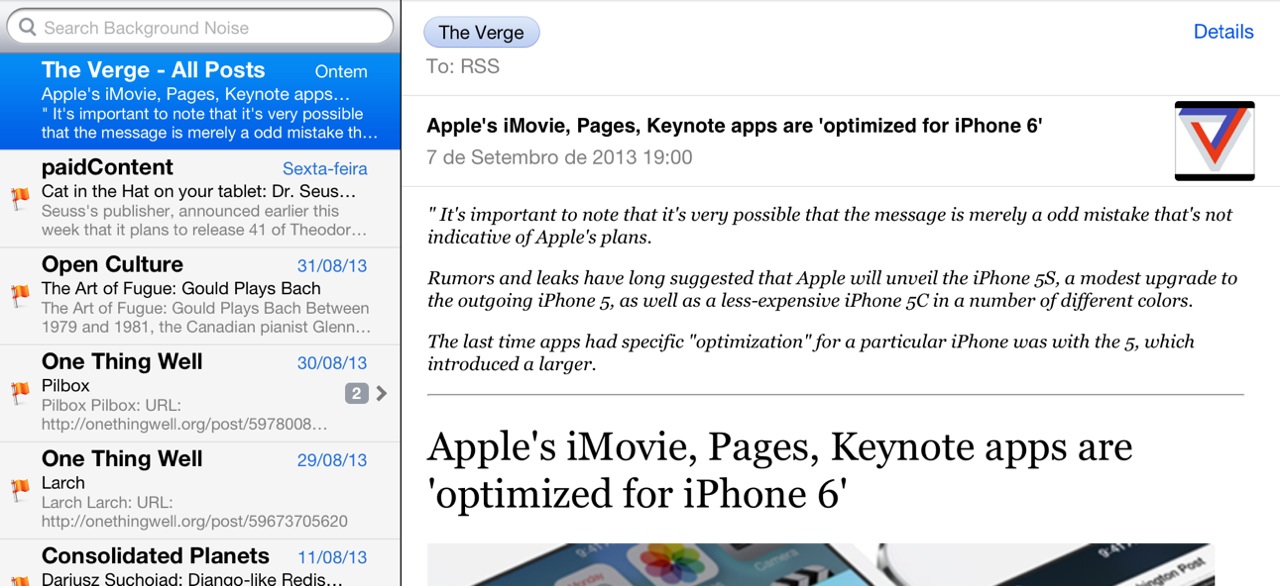
It’s fairly dumb (and mostly redundant for astroturfing feeds like Engadget that consist mostly of summaries), but I’ve found it to be a pretty good gauge for whether or not the article is worth reading at all, and very effective when reading news on a phone.
I expect the next step will probably be making it a lot smarter, but that will have to wait3.
Writing
Rather to my surprise I managed to sneak in some writing amidst all the lounging and traipsing around the country, largely thanks to Editorial – it’s wonderful, and I’ve been having tremendous fun using it.
Pretty much everything I’ve written since it came out has been written and revised on it, and I already have workflows for auto-linking text, fetching snippets of text from Evernote and automating image cropping and resizing.
All I need right now is for the official Dropbox iOS app to support proper folder renaming and individual file copying (why it lacks either is totally beyond me – I can only move stuff around inside it).
That and my RSI to go away – I still haven’t been able to shake it off completely, it seems, even on vacation.
Getting Jobs Done
I’ve also been tinkering with Python threading (since I can’t use gevent or multiprocessing on the iPad), and refactored the homegrown job queue I mentioned in passing earlier into something that looks and feels a lot like Celery, but for use inside a single process.
The library code is on this branch of my experimental RSS aggregator, and you use it very much like you’d use Celery:
@task(max_retries=3)
def worker(item_list):
for item in item_list:
item_worker.delay(item)
@task(max_retries=3)
def item_worker(item):
# do something frightfully complex with item
return "Boy, that was tough, but I've processed %s" % item
.delay() marshals the arguments and queues the task, giving you a Deferred object you can use to reference the actual result later (including any exceptions), and I’ve allowed for automatic task retries, priorities and pool size limits.
You can even run multiple thread pools for different sets of workers, making it pretty easy to put together relatively complex data processing flows inside the same process – just add Queues and stir.
What Didn’t Happen
Well, as it turns out I didn’t rest as much as I wanted to, or even touched any of the projects I originally planned (for starters, I had intended to give yaki-tng a sizable boost) – nor did I finish my book stack, watch all the videos I have been queueing up, etc.
But I did catch some pretty seashells, and the kids had plenty of fun.
-
To be honest, even the iPhone 5 seems too big these days. It’s been a bit of a pain from the start, but given the established trend toward larger screens I don’t think this will change (at least for my definition of “better”, or for common sense ergomomics). ↩︎
-
Pebble is the only sensible hardware out there right now, but it would have to be slimmed down a tad for me to consider wearing one. ↩︎
-
I really ought to have used NLTK and a decent tokenizer, but I was going for minimal code with maximum effect – doing it “right” would have meant a considerable amount of fiddling with NLTK corpuses and whatnot, which would be redundant when I have a strong feeling I’ll be re-doing it in another programming language soon. ↩︎