 Rui Carmo
Rui Carmo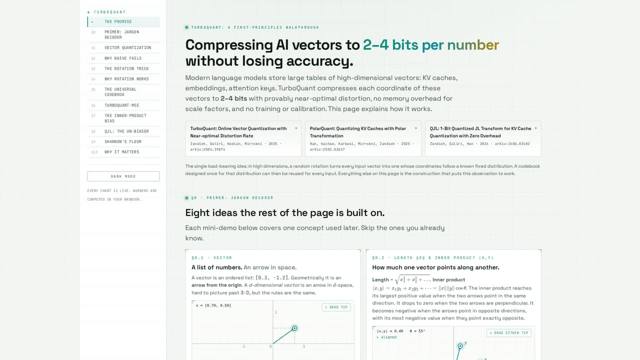
An interactive, beautifully executed walkthrough of vector quantization – compressing the KV caches and embedding tables that make modern language models so expensive to run, down to 2–4 bits per number without meaningful accuracy loss. The kind of thing that makes you wish more people explained dense technical material this way: live sliders, animated diagrams, intuition built up incrementally before the math arrives. Bravo.
Whoever built this put serious thought into the pedagogy, not just the implementation. Bravo.