 Rui Carmo
Rui Carmo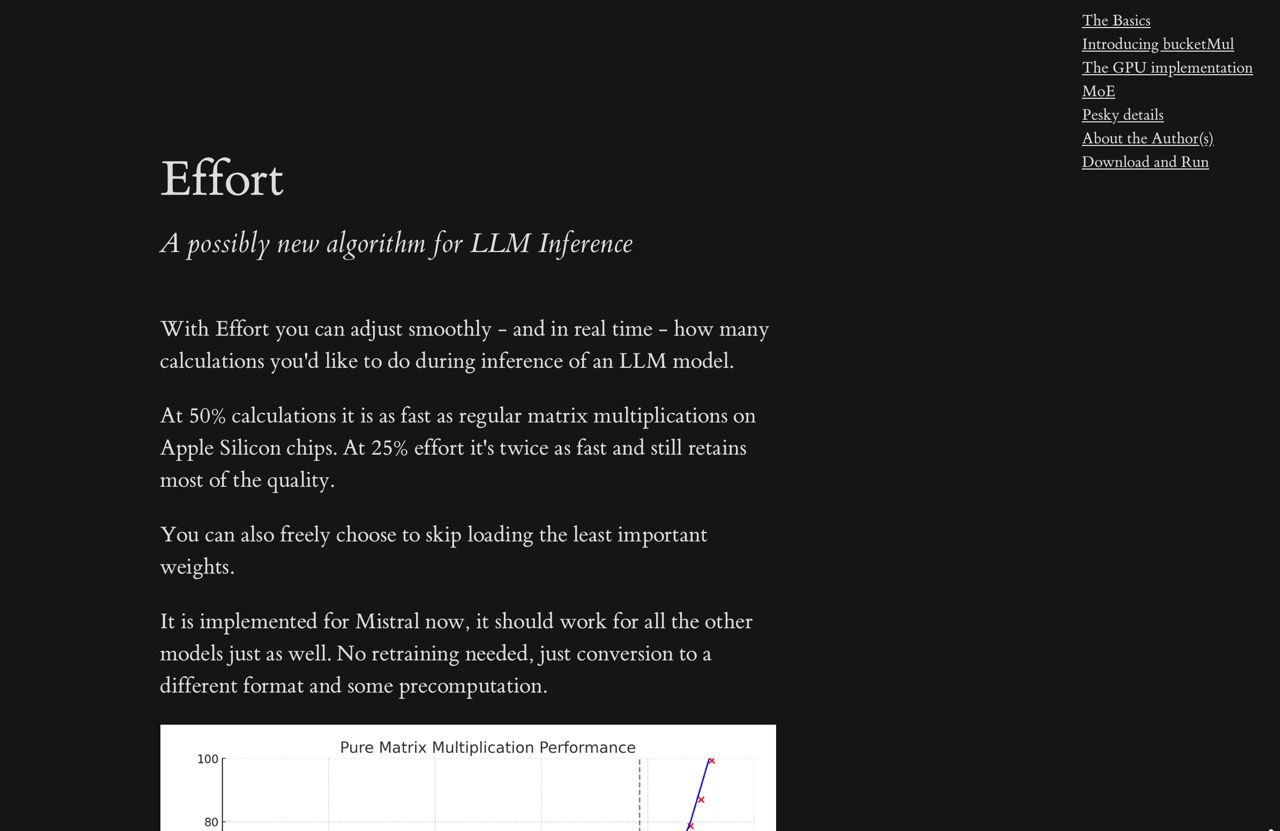
I’ve been pointing out that LLMs are barely optimized for ages now, so here’s another example of possible inference speedups that seems very promising (it works somewhat like on-the-fly distillation).
If this technique checks out and ends up implemented in mainstream tooling like ollama, it’s going to significantly lower compute and memory requirements for a bunch of scenarios.