 Rui Carmo
Rui CarmoThis is going to be a slightly different review, since it is not about a finished product–I’ve been sent an early sample of ArmSom/BananaPi’s upcoming AI module 7 (which will be up on CrowdSupply soon), and thought I’d share my early impressions of it.
Disclaimer: ArmSom provided me with an AIM7 and an AIM-IO carrier board free of charge (for which I thank them), and besides this piece following my review policy, I should reinforce that this is about a crowdfunding project, so there’s no guarantee that the final product will be exactly the same as the one I received.
Hardware
The AIM7 itself is a straightforward module patterned after the NVIDIA Jetson, with the same DIMM-like connector and onboard RAM and eMMC storage:
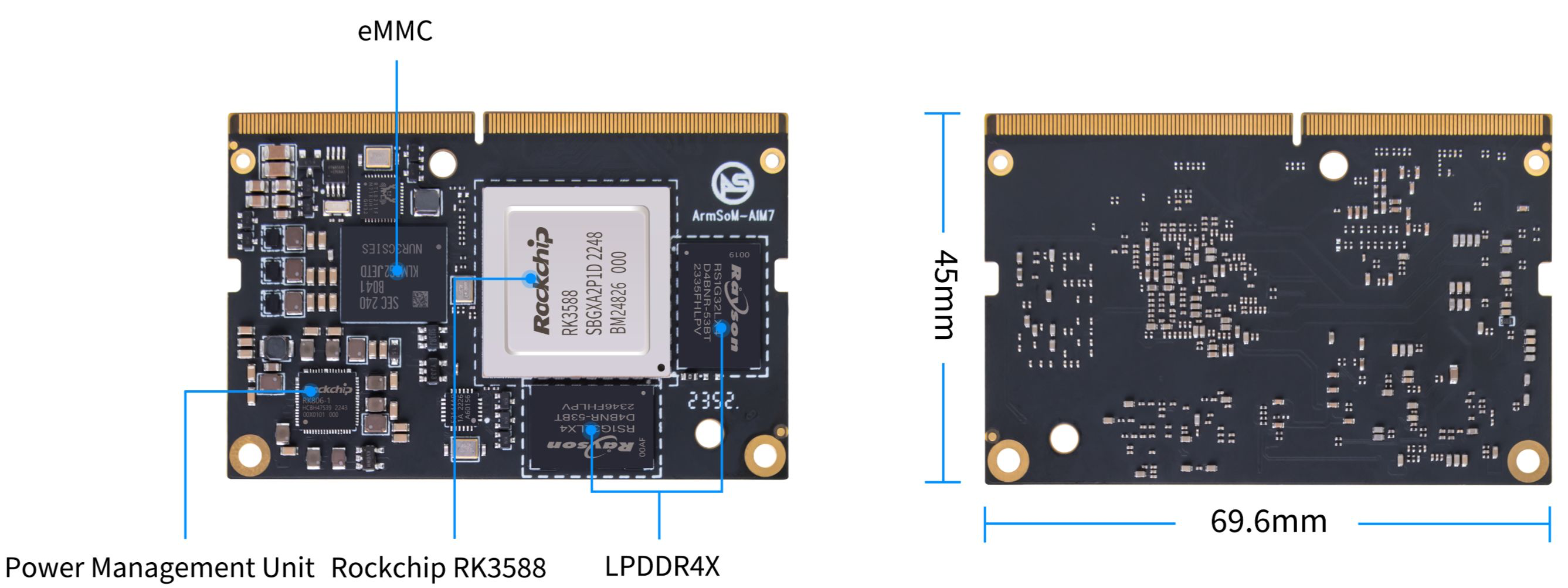
In case you’re not familiar with the chipset, these are the baseline specs:
- 4xARM Cortex-A76 + 4xCortex-A55 CPU cores
- Mali-G610 MP4 GPU
- 3-core NPU capable of 6 TOPS
- up to 32GB of LPDDR4 RAM
- up to 128GB of eMMC storage
I got an 8GB RAM/32GB EMMC board, which, to be honest, is very tight both RAM and storage-wise–it is certainly too little RAM for most of the AI workloads I tried, and fairly limiting for development considering that there is no other way to get high-speed storage hooked up.
But as we’ll see later, it might be perfectly suitable for industrial applications, not GenAI flights of fancy.
Thermals and Power
The module did not come with a thermal solution, so I resorted to my usual set of copper shims to keep it (quietly) cool. In that respect (and power consumption) it was not substantially different from any of the many devices I’ve tested, ranging from 4 to 11W (typical use vs full CPU load).
I/O
The carrier board is where all the I/O action is–besides being powered via a 12V barrel jack or USB-C (I chose the former this time around), it has 4 USB-A ports, HDMI, DisplayPort, a single Gigabit Ethernet port, and the usual set of hardware ports–40-pin GPIO header, MIPI-CSI/DSI, a microSD card reader, and an M.2 E-key slot for Wi-Fi:

Besides the single carrier board, the BananaPi wiki page hints at a 4-module AI edge gateway, so there’s clearly potential for building ARM clusters here.
Meet The Jetsons
Putting the AIM7 side-by-side with a Jetson Nano, the similarities are obvious:

ArmSom’s Crowdsupply page has a quick comparison with the Jetson Nano with some benchmarking information, so I won’t spend a lot of time on that here other than say that the modules are actually meant to be pin-compatible.
That said, I couldn’t run a set of comparative benchmarks for a couple of reasons: The 5V supply I got for the Jetson Nano died sometime late last year, so I can’t power it right now–but even if I tried exchanging carrier boards, the Nano I have was running a pretty old version of Ubuntu and CUDA, so it would actually be hard to get a meaningful comparison.
In truth, there’s just too little modern code that will actually run on this particular revision of the Nano unless you craft your own.
So, does the AIM7 replace the NVIDIA Jetson? Well, considering software alone the short answer is “no if you really need to use CUDA”, but I address that point below.
In short, it offers an interesting alternative if you care to venture into the waters of Rockchip’s various NPU libraries–which have actually improved quite a bit over the past few months.
Base OS
The board shipped with Debian Bullseye (11) and kernel 5.10.160, which feels a little dated but is par for the course in the Rockchip universe.
Since there is no Armbian support for this board yet, I just reset the locale settings to en_US.UTF-8 (it came with the usual Chinese locale) and made do with it:
uname -a
Linux armsom-aim7 5.10.160 #98 SMP Thu Jan 2 15:14:22 CST 2025 aarch64 GNU/Linux
locale
sudo vi /etc/locale.gen
sudo locale-gen
sudo vi /etc/default/locale
GenAI, LLMs and RKLLM
And yes, of course I ran DeepSeek on it as soon as I got it. It’s a great party trick, but it doesn’t really do much other than show off the NPU’s capabilities.
What I’ve found much more interesting is running a few other models directly on the NPU, like marco-o1 and gemma-2:
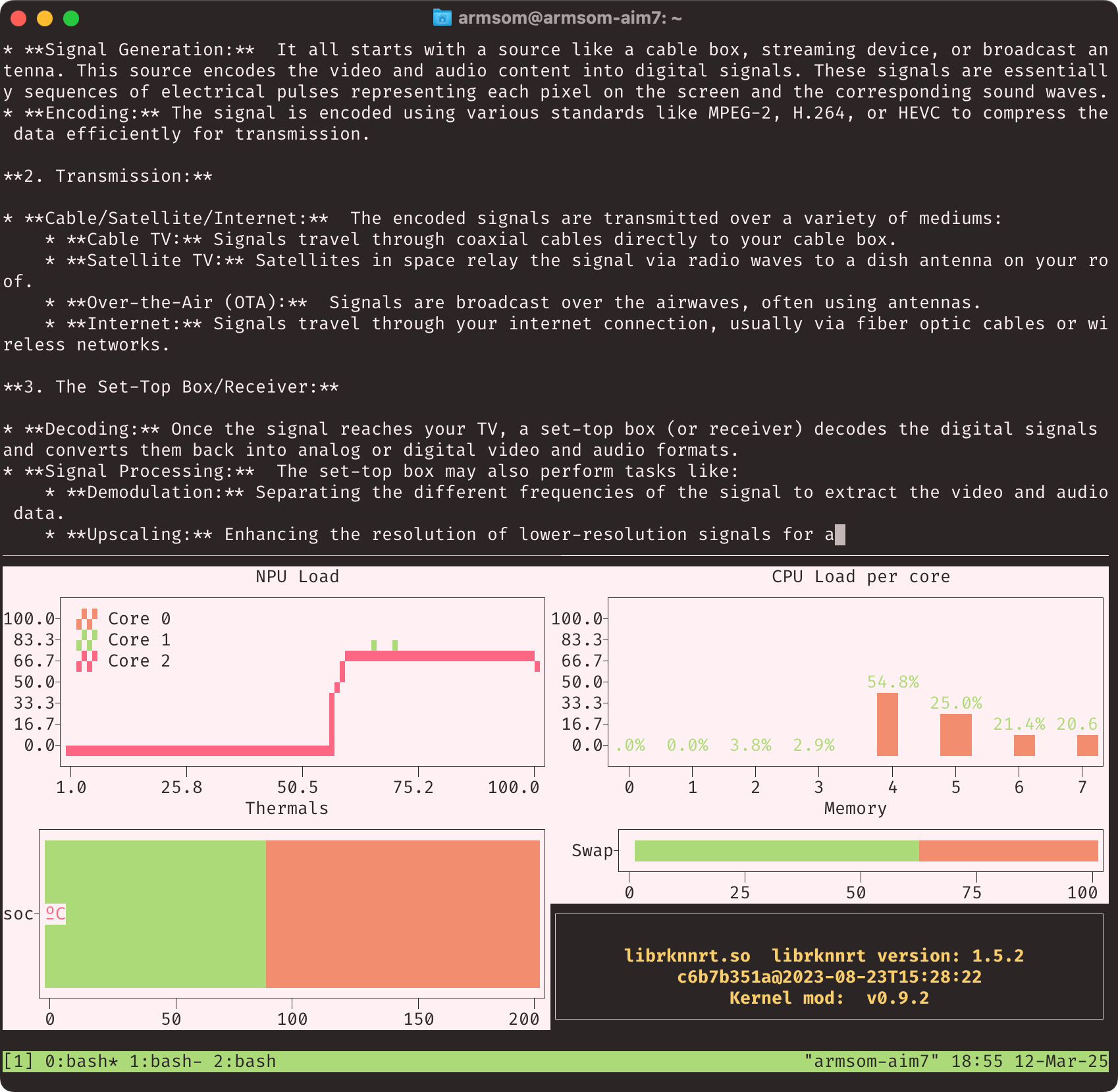
However, any of them was a pretty tight fit–the 8GB of RAM was the main constraint, and I couldn’t get gemma-3:4b to run at all–although I was able to run gemma-3:1b under ollama (because I couldn’t convert it–more on that below).
So, in short, if LLMs are what you intend to play with, go for a bigger SKU with more eMMC storage and RAM–the 8GB/32GB version is just too tight for anything other than a few small models, and even then only one at a time.
Notes on Tooling
One of my perennial gripes with the Rockchip toolchains is that a lot of the rkllm code has been patchy and hard to use. However, a few brave souls have forged on, and these days rkllm-1.1.4 is actually pretty usable.
And there are a few other tools available for the RK3588’s NPU that might make things easier for people looking to experiment with LLMs, including two I’m using in the screenshot above:
rkllamagives you anollama-like experience (even down to being able to download pre-converted models from the cloud, in this case directly from Huggingface)rknputopis the closest thing to annvtop-like view of NPU usage (albeit still a little buggy, and including CPU, RAM and temperature)
There are also (finally) documented and reproducible ways to convert models to .rkllm format, and (even better) a surprising amount of pre-converted models on Huggingface iike these.
LLM Caveats
Converting models has actually become somewhat trivial, provided you use relatively old model families–for instance, I could not convert phi4 or the latest gemma3 to .rkllm format because:
- I had a bunch of issues with the
phi4tokenizer, so even though I could convertphi3the same conversion code wouldn’t work forphi4. gemma3, which just came out as I am finishing this post, is simply not supported byrkllmsince the model actually declares itself as a different “family”.
Now, rkllm won’t be updated for a while yet, but hacking at the model tree with torch and transformers isn’t something I have the time or patience to do these days, so I wasn’t able to devise a suitable workaround–yet.
But the general approach is pretty simple:
from rkllm.api import RKLLM
from os.path import basename
import torch
# tried to use these to convert the tokenizer
from transformers import AutoTokenizer, AutoModel, PreTrainedTokenizerFast
#...
modelpath = './Phi-3-mini'
llm = RKLLM()
# options ['cpu', 'cuda']
ret = llm.load_huggingface(model=modelpath, model_lora = None, device='cuda')
# ret = llm.load_gguf(model = modelpath)
if ret != 0:
print('Load model failed!')
exit(ret)
# break out the parameters for quicker tweaking
ret = llm.build(do_quantization=True,
optimization_level=1,
quantized_dtype="W8A8",
quantized_algorithm="normal",
target_platform="RK3588",
num_npu_core=3,
extra_qparams=None,
dataset=None)
if ret != 0:
print('Build model failed!')
exit(ret)
# Export rkllm model
ret = llm.export_rkllm(f"./{basename(modelpath)}_{quantized_dtype}_{target_platform}.rkllm")
if ret != 0:
print('Export model failed!')
exit(ret)
There are a few other options you can tweak, but with my 3060 converting a couple of small models took mere minutes.
Vision, Speech and RKNN
However, I don’t think the AIM7 is going to be used for running LLMs in real life.
For most people rknn-toolkit2 is likely to be of more interest, since it allows you to use whisper and various versions of YOLO (that you can get from the model zoo ) for speech and image recognition.
I know for a fact that the Jetson Nano was extensively used in image processing and defect detection in manufacturing lines, and although I haven’t had the time to actually test YOLO on this board yet, I know that the AIM7 is a suitable replacement because that’s what many other RK3588 boards are already being used for.
Which is why having an RK3588 board that is a direct replacement for a Jetson (which, by the way, tends to be picky about power and much hotter and noisier) makes a lot of sense.
I am not sure about video frame rates since that will always be heavily model-dependent, but earlier RK3588 boards with the original rknn toolkit were able to go well over 25fps, and I suspect that will at least double with some careful optimization.
But, most importantly, it isn’t hard to find example code that uses rknn for object detection and there is now even official support from tools like Frigate, so it’s certainly no longer an unexplored path.
Conclusion
I like the AIM7–I can’t really compare it directly to the other RK3588 SBCs I reviewed in terms of features (other than the chipset and base I/O) because it is very specifically designed to replace or compete with the Jetson, but, ironically, out of all of them it is the best suited for industrial applications–where you don’t really need NVMe storage, and the even 32GB will be plenty to have multiple copies of vision models like YOLO.
I just wish it had come with more RAM as far as I’m concerned…