 Rui Carmo
Rui CarmoThere is a very frequent and particularly messy ETL scenario that I like to call “death by a million files” in which large corporations find themselves in need of collecting and processing thousands of old-school CSV and XML files (or worse) and take them to the cloud, which is something that no traditional ETL tool can do efficiently (especially not graphical ones).
Last week I sat down during one of those engagements and drew up a pipeline (partially) based on a set of Azure Functions that took those files off a blob store, parsed them, collated the data and inserted it into a SQL database.
A twisty little maze of queues, all alike
I was working my way through how many queues I’d need to thread data through a handful of different transformation functions until I remembered that Azure has an equivalent to AWS Step Functions under the form of Durable Functions, an extension to the Azure Functions stack (which, incidentally, is fully Open Source) that lets you string Functions together in complex orchestration patterns without having to manage queueing myself.
So yes, the serverless revolution is real. You can do pretty interesting things without touching a VM, and with a pretty great development cycle–git push your code, have the service set things up and fetch dependencies for you (like I do in piku, actually), and everything runs (and scales up and down) on-demand without having to mess around with cron jobs, and with nice monitoring to boot:

From ETL to static site generation
This approach is extremely useful for a number of scenarios and I needed not only a re-usable sample but also something I could fiddle with at length (I still don’t like coding in NodeJS, but I have hope of turning that distaste into a useful skill), so after coding the first iteration of the PoC I decided to generalise things a bit and turn it into a simple, fully serverless static site generator:
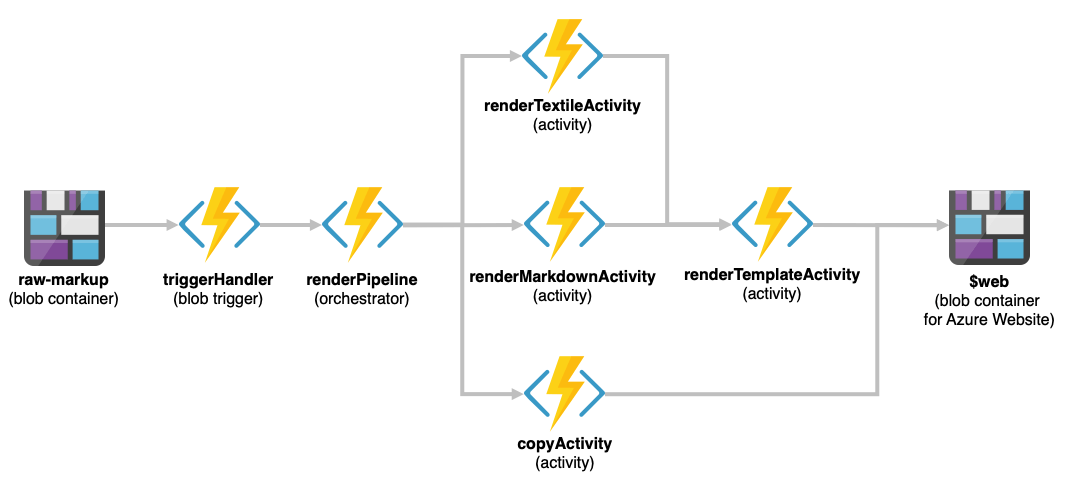
And so far, it’s working out really well, to the point where I’ve thrown most of this site at it and (other than lacking proper design and breaking in several pieces due to missing functionality) it can readily cope with thousands of files a second once it’s warmed up.
Considering that the code for the above currently clocks in at around 200 active, useful lines as of this writing, I would say this is pretty damn good bang for the buck (and it should cost much less than a couple of Euro to run per month, too).
Although there are a few constraints when compared with running a site generator in a standard execution environment (for instance, you can’t go off and enumerate other files in the same folder while rendering a page without some planning), it seems I finally found something that can, with a little more work, provide an interesting alternative to my current wiki engine.
As long as I have the patience to re-code some of the smarter bits in JavaScript, that is…