 Rui Carmo
Rui CarmoIt’s been a while since I posted something a little more technical, so I spent a little while trying to get the blog engine to deal with Jupyter notebooks and decided to have a serious go at it.
The Case for Literate DevOps
As you might well know by now, Azure is a big part of what I do on a daily basis. But being the stickler that I am for both documentation and automation, I’ve found PowerShell and the Azure CLI (even the spanking new one that’s in preview now) a bit limiting.
The whole point of orchestration is to write scripts to do the work for you, but shells of most kinds are awkward and don’t help you document what you do in any way.
On the other hand, when you’re at the early stages of iterating a design, full-blown configuration management tools can be a bit overkill. Well, except maybe for Ansible, which I love, but which being IaaS-centric, doesn’t cover all the Azure APIs.
And then there’s the whole “infrastructure as code” thing. Yes, the result of your work has to be a versionable artifact (a nice git repo with a well-written README and enough fail safes to make sure anyone else can use it to deploy your solution), but when you’re living on the bleeding edge and tools lag behind, how do you iterate quickly in the early stages and get a head start on documentation at the same time?
Jupyter Ascending
As it turns out, the answer was staring me in the face. I use Jupyter on a daily basis for analytics and ML work, and the latest versions have become so frictionless (even down to supporting Ctrl+Shift+P for a command palette like most of the editors I use) that there’s really no contest.
Nearly two years ago I was happily fiddling with the Azure APIs using nothing but Python, so all I needed was a simple, up-to-date way to deal with bleeding edge Azure APIs (both the Python SDK and az work great, but they’re focusing on stable stuff).
After poking around a bit, I decided to use Guy Bowerman’s REST API wrapper, which is very easy to extend with arbitrary endpoints and, combined with a couple of wrappers, allows me to write neat, concise code in my notebooks.
Wanted: a Generic Cluster Template
So, what’s a good use case I can apply this to?
Well, in my line of work, I need to create all sorts of clusters. In fact, the first thing I did at a customer back when I joined up was deploy a Hadoop cluster, and as it turns out I did it using Azure Resource Manager Templates, which were the new hotness at the time.
There’s a learning curve involved, as usual in any orchestration mechanism, but the key point here is that ARM templates provide you with a declarative way to provision (and update) Azure resources in JSON syntax – so you can write a template, deploy it, and then change it and deploy it again as needed – either to update a previous solution, or to duplicate it elsewhere.
In this post, I’m going to provide a (relatively) quick overview of how to go about creating and deploying such a template.
Later on, in later posts, we’ll go back and re-visit some details of how the templates are built internally and enhance them.
The Bare Essentials
Regardless of what else I pile up on top, the bare bones of what I usually need is this:
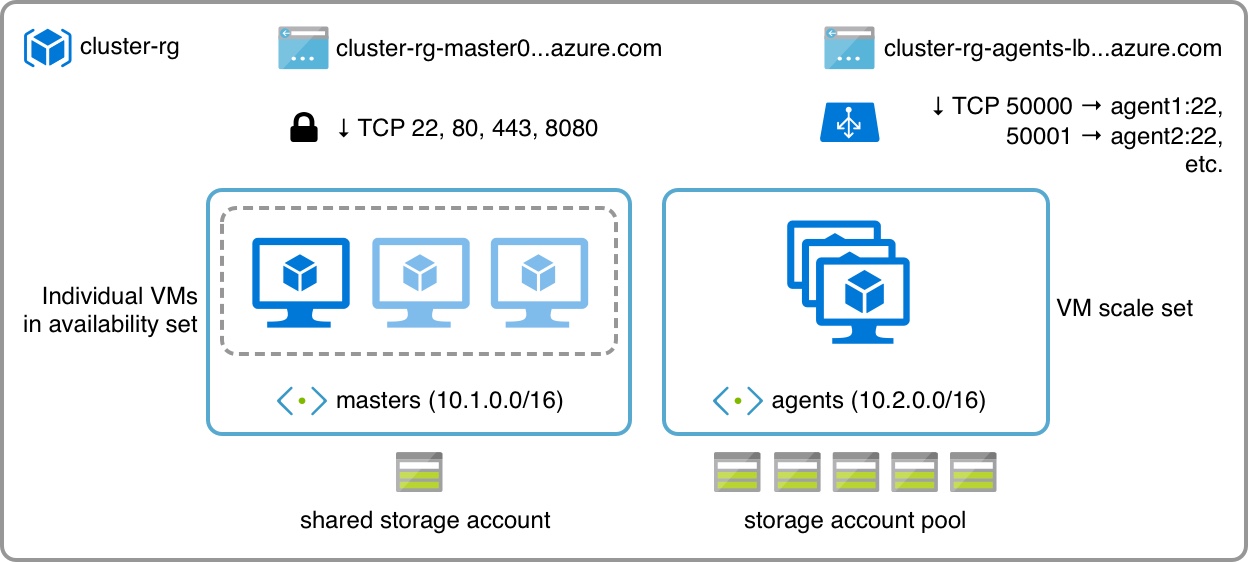
It essentially boils down to two things:
- A “permanent” set of master machines/front-ends
- A “volatile” set of agents/back-ends that I can resize at will
The smallest cluster I need is usually a single master node (which is also the only machine visible from the outside) and a couple of workers, so that is what my template is going to default to.
There are, however, a bunch of other things in the diagram that warrant some explanation, especially if you’re not into Azure.
Azure IaaS in a Nutshell
Here’s the nickel tour to the basic concepts:
Azure resources are typically managed in resource groups (i.e., many to a subscription), which are usually tied to a location (i.e., West Europe, Japan, etc.) and contain computing, storage and networking resources (as well as PaaS services, but I’ll leave those for a later post).
Networking is pretty straightforward: You create VNets, which can be split into subnets. Subnets provide DHCP (including DNS configuration) to machines placed in them and outbound connectivity via NAT – if you want inbound connectivity, you have to either allocate a public IP address and define a network security group to allow inbound ports to each machine, or use a load balancer to do port mapping (I’m doing both in the example above, and we’ll see why later).
Virtual machines have a few more nuances. Each individual VM has (at least) one network interface and (at least) one disk volume. Disk volumes live in blob storage, which in turn is managed in storage accounts (which is where you define performance and redundancy for those volumes).
So to create a VM instance, you have to have a storage account and a subnet to put its disk volume and network interface in – the portal provides sane defaults for those, but at an API level you need to understand this.
Building Upon The Basics
You can (and should) group instances with similar roles into availability sets, which tell Azure to keep at least one of those instances up and running in case of maintenance events – that’s what I’m doing with the master nodes above.
But if you need to scale up or down your infrastructure at will and have multiple interchangeable workers, then you can use VM scale sets, which effectively run the same machine image – and since we may well need to run hundreds of those, their disk volumes are best distributed across a pool of storage accounts.
And, to make it slightly easier to access individual VMs in a scaleset from the outside, you can set up a load balancer (which, incidentally, is the first thing I remove – but we’ll get to that on a later post).
Scale sets, as the name implies, come with quick and easy ways to scale up computing capacity as necessary, including autoscaling based on specific metrics – although I’ll be using the API to have full control over scaling, I’ll probably write about autoscaling on a later post.
Getting our Hands Dirty
Now that we’ve got our conceptual groundwork covered, we need to get started on talking to the Azure API. That was one of my own pain points as I started to use Resource Manager, but these days it’s a lot simpler. Let’s just dive in:
# pip install azurerm -- https://github.com/gbowerman/azurerm
import azurerm
from azutils import * # utilities and private wrappers
from credentials import *
# We're going to pay a visit to Japan
RESOURCE_GROUP = "cluster-demo"
LOCATION = "japanwest"
ACCESS_TOKEN = azurerm.get_access_token(TENANT_ID,
APPLICATION_ID,
APPLICATION_SECRET)
len(ACCESS_TOKEN)
1088
My, what a big token we’ve got. Let’s create a resource group to hold our project:
# returns a Response object
resp = azurerm.create_resource_group(ACCESS_TOKEN,
SUBSCRIPTION_ID,
RESOURCE_GROUP,
LOCATION)
# Struct is my helper class to navigate inside JSON structures
resp, Struct(resp.text).properties.provisioningState
(<Response [201]>, u'Succeeded')
This is all fine and good, buy you’re probably asking yourself how to obtain the authentication credentials. Let’s talk about that for a bit, because it’s usually the first stumbling block.
Getting a Service Principal
Any application that needs to talk to the Azure APIs has to be pre-registered onto Azure Active Directory as a service principal – i.e., a registered application that is given a specific role (in our case, the minimum required role is Contributor) to services in a given scope. I usually create a principal that can manage the entire subscription, but if you intend to manage production deployments you should limit that scope to be, say, a single resource group – that way you can make your application able to manage just its own resources.
The process to do that is documented here, and in the end you’ll have three pieces of information:
- A tenant ID
- An application ID
- An application secret
With those, the API wrappers then request a (short-lived) access token from Active Directory to place Resource Manager API calls. In Python, that is usually done with the adal library (simplest possible example here), which azurerm employs.
Template Creation Strategies
So let’s get going. You fire up your editor, grab a sample template from somewhere, and start hammering code. Right?
Well, no. In fact, if you read through the whole best practices documentation, you’re already doing something wrong. Why?
Because you’re assuming it’s a single template.
In fact, it makes a lot more sense (for my use case) to split things into a base template (which holds all the “permanent” resources, such as networking) and an overlay template to hold the dynamic, throwaway resources.
There are multiple advantages to this approach. First off, you can update and re-use each template separately. You can also mix and match different kinds of masters and agents, and even (with a little care) deploy multiple sets of agents atop the same base template.
Attentive readers will by now have caught on that if I need to do that, then I need to plan my networking a little better than for this example – and you’re right.
Although I only split this into two templates (because I already know I’ll be re-using the same network config time and again), the best way to do things would actually be to have three separate templates:
- Common Infrastructure (networking in this case)
- Front-end tier (masters in this case)
- Back-end tier (agents in this case)
For production deployments, things get a little more complex. It’s not unusual to have a dedicated storage template, for instance, and I’m not even factoring PaaS into the mix.
The key point here is that you need to plan ahead. Fortunately, it’s easy to iterate quickly and document what you do (which is kind of the whole point of this post, really).
And, in fact, I did that for you already – otherwise this post would have been a lot more than an overview.
If you want to read along, you can download both templates I’ve created (and the azutils module I’m using for these snippets) from this GitHub Gist.
No, seriously, don’t. At least not just yet, because wading through hundreds of lines of JSON isn’t anyone’s cup of tea, and it’s not really necessary yet, because we’re going to take a little peek into what’s inside both templates.
Parameters
Templates can, of course, take parameters. I won’t go into much detail on what kinds are available and the full range of ways they can be instantiated (that’s what the docs are for), but we can take a look at what’s defined in the example:
base = Struct(open("azure-minimal-cluster-base.json").read())
overlay = Struct(open("azure-minimal-cluster-overlay.json").read())
sorted(map(str,base.parameters.keys()))
['adminPublicKey',
'adminUsername',
'asFDCount',
'asUDCount',
'customData',
'masterCount',
'nsgName',
'prefix',
'publicIpAddressType',
'saType',
'vmSize']
sorted(map(str,overlay.parameters.keys()))
['adminPublicKey',
'adminUsername',
'agentCount',
'customData',
'saType',
'vmSku',
'vmssName']
Fairly straightforward, right? let’s take a look at masterCount, which tells us how many master nodes to create:
base.parameters.masterCount
{
"defaultValue": 1,
"metadata": {
"description": "Master count"
},
"type": "int",
"allowedValues": [
1,
3
]
}
It has a sensible default, some metadata (used by the portal to render help prompts), and a list of allowed values that are validated by the Resource Manager upon deployment. Let’s look at the equivalent for the overlay template:
overlay.parameters.agentCount
{
"defaultValue": 2,
"metadata": {
"description": "Number of agent VM instances (100 or less)."
},
"type": "int",
"maxValue": 100,
"minValue": 1
}
Again, fairly straightforward. There are plenty of other parameters to examine, but let’s leave them for another post.
Sharing is Caring
We split our solution into two templates, but it’s useful to understand how to share resource definitions between templates. So let’s see what kind of resources each one holds:
map(lambda x: str(x.type.split("/")[1]), base.resources)
['storageAccounts',
'virtualNetworks',
'virtualMachines',
'availabilitySets',
'networkInterfaces',
'publicIPAddresses',
'networkSecurityGroups']
map(lambda x: str(x.type.split("/")[1]), overlay.resources)
['storageAccounts',
'publicIPAddresses',
'loadBalancers',
'virtualMachineScaleSets']
As you might surmise from the above, the base template holds the virtualNetworks definitions, which include addressing for both subnets. Let’s take a look at it:
base.resources[1].properties
{
"subnets": [
{
"name": "masters",
"properties": {
"addressPrefix": "10.1.0.0/16"
}
},
{
"name": "agents",
"properties": {
"addressPrefix": "10.2.0.0/16"
}
}
],
"addressSpace": {
"addressPrefixes": [
"10.0.0.0/8"
]
}
}
But how does the overlay template get to know about this?
Well, I happen to know that it references the agents subnet directly as part of its virtual machine profile. Let’s look at what’s in there by inspecting the template:
# the first interface defined for the machine profile
eth0 = overlay.resources[3].properties.virtualMachineProfile.networkProfile.networkInterfaceConfigurations[0]
# the first configuration for the interface
eth0.properties.ipConfigurations[0].properties.subnet
{
"id": "[concat('/subscriptions/', subscription().subscriptionId,'/resourceGroups/', resourceGroup().name, '/providers/Microsoft.Network/virtualNetworks/', 'cluster', '/subnets/', 'agents')]"
}
Bit of a mouthful, I know. But if you take the template functions out of the way, Azure resource IDs make a lot of sense:
/subscriptions/<id>/resourceGroups/<name>/providers/<kind>/<naming>
So it’s actually quite easy to refer to an existing resource that is not part of your template (although some resources have sub-names).
In our case, and once you whittle away the template functions, the overlay template references the agents subnet like this:
/subscriptions/<id>/resourceGroups/<name>/providers/Microsoft.Network/virtualNetworks/cluster/subnets/agents
Which is pretty straightforward, really. Of course, you don’t want to hard-code resource names on your production templates – my example only does this for the sake of clarity, and even then I always use subscription().subscriptionId and resourceGroup().name to have them resolved at deployment time.
Pro Tips * Use Visual Studio Code to edit the templates by hand, but with on-the-fly JSON schema validation. By all means try the full-blown Visual Studio editor, but in my experience you only truly understand things when you do them by hand. * In the first couple of iterations, avoid using
[concat(variable("foo"))]constructs until you’re sure you need them. They help a lot when templates get complex and you start needing unique IDs, but they tend to obscure how identifiers are built (I removed most of them from my examples for clarity, and this this is another reason why I tend to avoid Visual Studio, which tends to auto-generate walls of text solely with variables). * When in doubt, check out the quickstart templates GitHub repo repository – chances are that someone has already done at least part of what you’re looking for. * Manage your templates withgit(or your favorite SCM poison). This is not optional, because you will find yourself scratching your head and wondering how to revert a “harmless” change.
Baby’s First Deployment
So, now that we have the templates, how do we actually use them?
Well, like I pointed out at the start, I usually iterate through these things very quickly, and neither PowerShell nor the Azure CLI are my cup of tea.
Remember the resource group we created at the start? Let’s check if it’s still there (I like to clean up stuff every now and then) and we’ll get started:
rgs = Struct(azurerm.list_resource_groups(ACCESS_TOKEN, SUBSCRIPTION_ID)).value
# sorry, guys, you only get to see my playground :)
for j in filter(lambda x: "japan" in x.location, rgs):
print j.name, j.location, j.properties.provisioningState
cluster-demo japanwest Succeeded
Now I can go on and deploy the template. Let’s do so and build a few little helpers along the way:
RESOURCE_GROUP = "cluster-demo"
DEPLOYMENT_NAME = "babys-first-deployment"
def do_deploy(group, name, template, params):
"""a little helper to load and deploy"""
tmpl = open(template).read()
resp = azurerm.deploy_template(ACCESS_TOKEN,
SUBSCRIPTION_ID,
group,
name,
parameters=json.dumps(params),
template=tmpl)
s = Struct(resp.text)
try:
msg = s.properties.provisioningState
except:
msg = s.error.code, s.error.message
return resp, msg
from base64 import b64encode
resp, msg = do_deploy(RESOURCE_GROUP,
DEPLOYMENT_NAME,
"azure-minimal-cluster-base.json",
{
"adminUsername": {
"value": "cluster"
},
"adminPublicKey": {
"value": "hmm. I need something to put here"
},
"customData": {
"value": b64encode("#!/bin/sh\n# empty bootstrap script")
}
})
resp, msg
(<Response [201]>, u'Accepted')
Well, so far so good. Let’s take a look at how it’s progressing:
def print_status(group, name):
resp = azurerm.list_deployment_operations(ACCESS_TOKEN,
SUBSCRIPTION_ID,
group,
name)
ops = Struct(resp)
# let's check each provisioning operation triggered by the template
for op in ops.value:
print op.properties.targetResource.resourceType, \
op.properties.provisioningState,
if "Failed" in op.properties.provisioningState:
print op.properties.statusMessage.error.message
else:
print ""
print_status(RESOURCE_GROUP, DEPLOYMENT_NAME)
Microsoft.Compute/virtualMachines Failed The value of parameter linuxConfiguration.ssh.publicKeys.keyData is invalid.
Microsoft.Network/networkInterfaces Succeeded
Microsoft.Network/publicIPAddresses Succeeded
Microsoft.Storage/storageAccounts Succeeded
Microsoft.Compute/availabilitySets Succeeded
Microsoft.Network/virtualNetworks Succeeded
Microsoft.Network/networkSecurityGroups Succeeded
Well, that makes perfect sense – I knew I needed a proper SSH key. Let’s rustle up a throwaway key with paramiko and have another go:
from os.path import exists
if not exists("paramiko.pem"):
from paramiko import SSHClient, AutoAddPolicy, RSAKey
k = RSAKey.generate(1024)
k.write_private_key_file("paramiko.pem")
with open("paramiko.pub", 'w') as f:
f.write("%s %s" % (k.get_name(), k.get_base64()))
resp, msg = do_deploy(RESOURCE_GROUP,
DEPLOYMENT_NAME,
"azure-minimal-cluster-base.json",
{
"adminUsername": {
"value": "cluster"
},
"adminPublicKey": {
"value": open("paramiko.pub").read()
},
"customData": {
"value": b64encode("#!/bin/sh\n# empty bootstrap script")
}
})
resp, msg
(<Response [200]>, u'Accepted')
print_status(RESOURCE_GROUP, DEPLOYMENT_NAME)
Microsoft.Compute/virtualMachines Succeeded
Microsoft.Storage/storageAccounts Succeeded
Microsoft.Network/networkInterfaces Succeeded
Microsoft.Network/publicIPAddresses Succeeded
Microsoft.Network/networkSecurityGroups Succeeded
Microsoft.Network/virtualNetworks Succeeded
Microsoft.Compute/availabilitySets Succeeded
That looks OK now. Let’s see how we can SSH in (I personally don’t like to leave SSH ports open on the Internet, but this is just a demo).
To do that, we’ll see if there are any DNS aliases provisioned in this resource group:
ips = Struct(azurerm.list_public_ips(ACCESS_TOKEN,SUBSCRIPTION_ID,RESOURCE_GROUP))
for ip in ips.value:
print ip.properties.dnsSettings.fqdn
cluster-demo-master0.japanwest.cloudapp.azure.com
Where did that come from, you ask? Well, here it is on the base template:
base.resources[5].properties
{
"publicIpAllocationMethod": "Dynamic",
"dnsSettings": {
"domainNameLabel": "[concat(resourceGroup().name, '-', parameters('prefix'), copyIndex())]"
}
}
You can see that I’m using the resource group name, a prefix (which is actually master by default) and an instance count to generate a unique DNS label for each machine.
Let’s try SSHing in now, from the comfort of Jupyter:
%%bash
# SSH in ignoring previous checks (i.e., reimaging machines a lot)
# and send the ugly SSH warnings to /dev/null
ssh -oStrictHostKeyChecking=no\
-oCheckHostIP=no -i paramiko.pem \
[email protected] \
ifconfig eth0 2> /dev/null
eth0 Link encap:Ethernet HWaddr 00:0d:3a:40:0e:3c
inet addr:10.1.0.10 Bcast:10.1.255.255 Mask:255.255.0.0
inet6 addr: fe80::20d:3aff:fe40:e3c/64 Scope:Link
UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
RX packets:580 errors:0 dropped:0 overruns:0 frame:0
TX packets:702 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:1000
RX bytes:227184 (227.1 KB) TX bytes:114566 (114.5 KB)
I’d call that a resounding success.
Conclusion
I think that’s more than enough for a first post – we’ve barely scratched the surface, since we only deployed one machine so far and used half the templates, but it’s a start.
Of course, I should reiterate that in real life (and at scale) you should build proper deployment tools – ideally something that will take your last template from git, run it through a continuous deployment system and have the results applied either via a full API wrapper or through something like Ansible or Terraform.
But I hope this demonstrates how easy it is to use Jupyter to quickly get up and running with Azure Resource Manager templates and APIs and have a nice, self-documented way of fleshing out, testing and debugging your templates.
And, again, this is just a quick overview – I plan on demonstrating how to script cluster deployments and tackle general lifecycle management on later (probably shorter) posts.
Which reminds me – it’s always a good idea to clean up after you do your tests:
for item in [RESOURCE_GROUP]:
print item, azurerm.delete_resource_group(ACCESS_TOKEN,
SUBSCRIPTION_ID,
item)
cluster-demo <Response [202]>
And that’s it, our cluster is gone. Next time around, we’ll add some agents to it.