 Rui Carmo
Rui CarmoAmidst the daily chaos of my current job, I still manage to find the time to code – partly because I need to build stuff to stay sane and partly because I often need to build PoCs and demos of varying sizes. Python is perfect for these scenarios, and now that I don’t have to support legacy Linux distros I can start using version 3 in earnest.
I’m not a fan of most of the syntax changes, but am glad 3.5 lets me get rid of the ugly @coroutine decorator and the weird yield from and just use async/await instead.
But, more importantly, I’m getting a significant performance boost from asyncio and carefully husbanded parallelism. I still can’t make good use of multiple cores inside the same process (I still have high hopes for PyPy STM in that regard), but splitting my stuff into multiple processes (each with its own uvloop-based event loop) and using ZeroMQ to exchange data is a lot more scalable than I expected.
The drawback is a certain loss of abstraction. ZeroMQ is fine in my book (I like being in control of how my app scales across cores/nodes), but having to constantly decide whether or not to use async bugs me, especially because it’s not fully baked yet. For instance, I love using generators (it’s the only real way to handle very large data streams), but asynchronous generators will only be available in Python 3.6, and even then I suspect comprehensions will only be half-baked.
Contrasting this to Go is interesting, since there I don’t have to faff about with inferior concurrency primitives and get staggering performance for just about everything. On the other hand, Go work flow and dependency management is still frustrating (I still hate GOPATH and largely refuse to rebuild my workspace around it) and I miss the nice Python library ecosystem every time I need to do data processing – the lack of nice ORMs and parsers is a recurring pain, so I invariably shy away from doing that sort of thing in Go.
Deployment
Getting stuff onto a server and making sure it can be managed sanely is something I decided to fix once and for all a few months ago – being a longtime fan of the Heroku model of git-based deployments I built piku to automate things for me, and it’s easily the best thing I wrote all year.
It now supports deploying Python 2 and 3 apps concurrently, and tweaks everything up the stack so that nginx and uWSGI can serve them without a hitch:
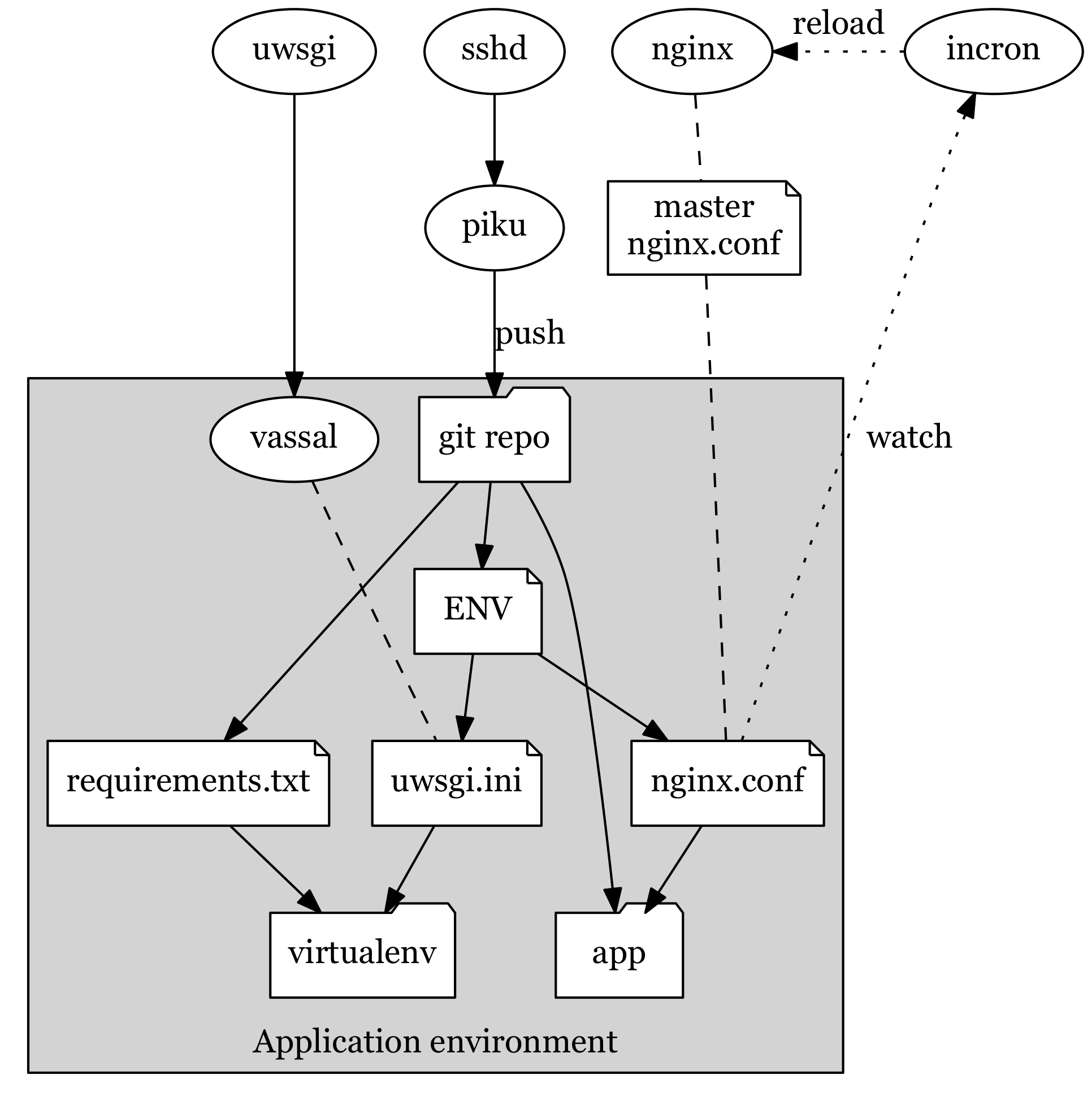
piku stack, in time-honored graphviz glory.But Docker is now de rigueur for deployments, so I’ve been building a stack I can rely on.
Last week I rebuilt a set of Alpine-based containers to make it trivial to package Python 3.5 applications with minimal footprint on both x64 and armhf, and am messing about with Docker Swarm (simply because it’s still the lowest common denominator) to figure out how best to tie it to piku in the long run – I’d love to push a JSON file out to piku and have it (re)deploy an entire stack across a couple of dozen nodes, and I’m positive I can do it right if I can find the time.
Looking Forward
A lot of what I do these days is around machine learning, so I try to add some fun angles to it by doing little tools and demos building upon the things above. The latest is newsfeed-corpus, and I’ve been pondering retrofitting bits of it to some of my older projects to bring them kicking and screaming into the Python 3 era.
But (and this is where I think Python 3 is failing) there is very little return in that investment. Things will not improve that much performance or maintenance-wise, and they won’t get substantially simpler, whereas rewriting some of my older stuff in Go will yield such tremendous performance boosts (and I will learn enough in the process) that it will nearly always amount to time well spent.
On the other hand, I miss Clojure and the clarity of thought that came with it. Given that Hy is still struggling to evolve after a year, finding a LISP or Scheme with a reasonable set of libraries that compiles down to native code would be a nice (if niche) way to get even more fun out of some of my projects…