 Rui Carmo
Rui CarmoAnd decided to dive back into the fray of rebuilding Yaki according to more modern standards.
This is what it’s starting to look like (even though I’m extremely likely to keep the current look and feel of this site as it is):
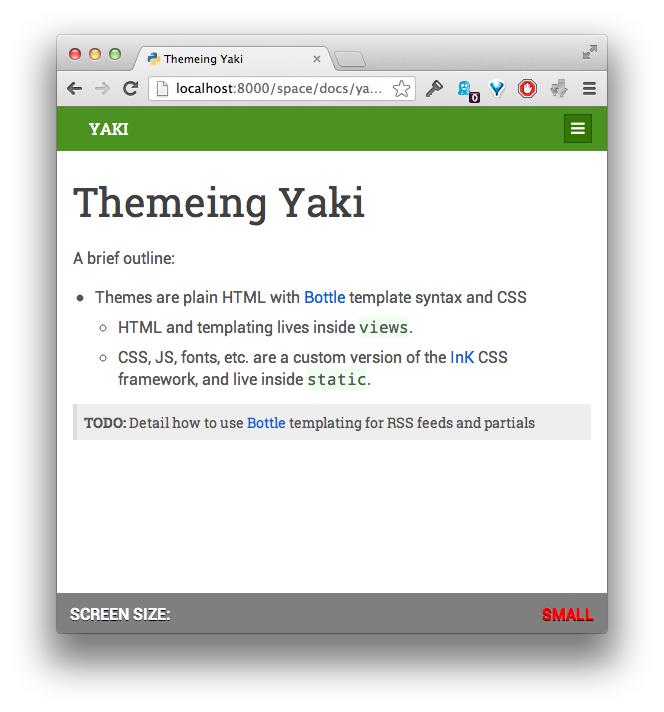
Right now, the core Wiki functionality is about done. It can handle most of my existing markup – both Markdown and Textile as well as the other variants – does auto-linking, inter-wiki linking, and has a nicer, more streamlined (and fully working) plugin subsystem.
The core is also (thanks to Bottle) around one tenth the amount of code of the current version, WSGI-compliant and much easier to tweak. In fact, the main rendering loop is now… a decorator:
def render():
def decorator(callback):
@functools.wraps(callback)
def wrapper(*args, **kwargs):
page = callback(*args, **kwargs)
page['data'] = BeautifulSoup(render_markup(page['data'],page['content-type']))
plugins.apply_all(kwargs['page'], page['data'], request=request, response=response, indexing=False)
return page
return wrapper
return decorator
And, for good measure, the main route looks like this:
@route('/space/<page:path>')
@timed
#@redis_cache('html')
@view('wiki')
#@redis_cache('markup')
@render()
def wiki(page):
s = Store(path_for(settings.content.path))
try:
result = s.get_page(page.lower())
except:
result = s.get_page('meta/EmptyPage')
return result
Note the commented decorators, which are a work in progress.
Right now the repo is in mild disarray as I move stuff around for refactoring and toss in oodles of pre-baked JS and CSS from my InK fork, but I hope to get started on the real nutcrackers (metadata plugins, full-text indexing and background tasks) in the next couple of weeks or so, leaving my trademark HTTP caching and tweaking for last.
The master plan is to leave the Yaki core as something anyone can run out of the box on just about any hardware (if anything, it’s going to be even faster and lighter) and leverage Redis and Celery for stuff like horizontal scaling, distributed indexing and whatnot.
Will those be overkill for a wiki engine? Why, of course. But where would be the fun in not doing them that way?